
最近,版主為 FakeRPC 增加了 WebSocket 協定的支援。這意味著,我們可以藉助其全雙工通訊的特性,在一個連線請求內發送多條資料。FakeRPC 目前最大的遺憾是,建立在 HTTP 協定上而不是 TCP/IP 協定上。因此,考慮 WebSocket 協定,更多的是為了驗證 JSON-RPC 的可行性,以及為接下來要支援的 TCP/IP 協定鋪路。也許,你從未意識到這些概念間千絲萬縷的聯繫,可如果我們把每一次 RPC 呼叫都理解為一組訊息,你是不是就能更加深刻地理解 RPC 這個稍顯古老的事物了呢?在編寫 FakeRPC 的過程中,我使用了 .NET 中的全新資料結構 Channel 來實作訊息的轉發。以伺服器端為例,每一個 RPC 請求經過 CallInvoker 處理以後,作為 RPC 回應的結果其實並不是立即發回給用戶端,而是透過一個背景執行緒從 Channel 取出訊息再發回用戶端。那麼,版主為什麼要繞遠路呢?我希望,這篇文章可以告訴你答案。
Channel 入門
Channel 是微軟在 .NET Core 3.0 以後推出的新的集合型別,該型別位於 System.Threading.Channels 命名空間下,具有非同步 API、高效能、執行緒安全等等的特點。目前,Channel 最主要的應用場景是生產者-消費者模型。如下圖所示,生產者負責向佇列中寫入資料,消費者負責從佇列中讀出資料。在此基礎上,透過增加生產者或者消費者的數目,對這個模型做進一步的擴充。我們平時使用到的 RabbitMQ 或者 Kafka,都可以認為是生產者-消費者模型在特定領域內的一種應用,甚至於我們還能從中讀出一點廣義上的讀寫分離的味道。
 生產者-消費者模型示意圖
生產者-消費者模型示意圖
羅曼·羅蘭曾說過,世界上只有一種真正的英雄主義,那就是在認清生活的真相後,依然熱愛生活。此時此刻,看著眼前的這幅示意圖若有所思,你也許會想到下面的做法:
class Producer<T>
{
private readonly Queue<T> _queue;
public Producer(Queue<T> queue) { _queue = queue; }
}
class Consumer<T>
{
private readonly Queue<T> _queue;
public Consumer(Queue<T> queue) { _queue = queue; }
}
我承認,這個思路理論上是沒有問題的,可惜實際操作起來槽點滿滿。譬如,生產者應該只負責寫,消費者應該只負責讀,可當你親手把一個佇列傳遞給它們的時候,想要保持這種職責上的純粹著實是件困難的事情,更不必說,在使用佇列的過程中,生產者會有佇列「滿」的憂慮,消費者會有佇列「空」的煩惱,如果再考慮多個生產者、多個消費者、多執行緒/鎖等等的因素,顯然,這並不是一個簡單的問題。為了解決這個問題,微軟先後增加了 BlockingCollection 和 BufferBlock 兩種資料結構,這裡以前者為例,下面是一個典型的生產者-消費者模型:
var bc = new BlockingCollection<int>();
// 生產者
var producer = Task.Run(() => {
for (var i = 0; i < Count; i++) {
bc.Add(i);
Console.WriteLine("Producer Write Item: {0}", i);
}
bc.CompleteAdding();
});
// 消費者
var consumer = Task.Run(() => {
while (!bc.IsCompleted) {
if (bc.TryTake(out var item)) {
Console.WriteLine("Consumer Read Item: {0}", item);
}
}
});
await Task.WhenAll(producer, consumer);
可以注意到,現在我們再去實作一個生產者-消費者模型,其難度基本為零。與此同時,BlockingCollection<T> 和 BufferBlock<T> 都是執行緒安全的集合,這可以讓我們在多執行緒環境下更加得心應手。回想我過去的種種經歷,每當我需要使用那些執行緒信號量進行執行緒同步的時候,我都不得不小心翼翼地在 Bug 邊緣遊走。那麼,你也許會問,既然我們已經有 BlockingCollection<T> 和 BufferBlock<T> 這樣的資料結構,為什麼我們還需要 Channel 呢?作為一名最普通不過的程式設計師,有無數多個 Bug 隨著時間的推移都慢慢消失了,而那些曾經令我們殫精竭慮的問題,同樣在不停地被重新整理著答案。
 BlockingCollection、BufferBlock、Channel 的效能對比
BlockingCollection、BufferBlock、Channel 的效能對比
如圖所示,我們測試了讀寫 10000 條資料的場景下,三種資料結構各自的效能表現,顯而易見 Channel 的效能是最好的,所以,你告訴我,這到底算不算一個理由,難道還有什麼東西比效能更令人興奮的嗎?當你的電腦顯示卡不能帶你領略刺客教條的「神話三部曲」,甚至連在本機部署 Stable Diffusion 都變成一種奢望的時候,你不得不承認,這一點點微不足道的效能最佳化,是這個預言摩爾定律將會失效的時代裡,所剩無幾的匠心獨運。
// 建立一個有限容量的 Channel
var boundedChannel = Channel.CreateBounded<int>(100);
// 建立一個無限容量的 Channel
var unboundedChannel = Channel.CreateUnbounded<string>();
好了,對於 Channel 我們該從哪裡開始說起呢?可以注意到,建立一個 Channel 是非常簡單的,除非你打算建立的是一個有限容量的 Channel。還記得我們一開始提出的問題嗎?在生產者-消費者模型中,一個容量有限的佇列,一定會無可避免地出現佇列「滿」的情形,此時,我們就需要制定某種策略或者機制來完善整個模型。對於這個問題,Channel 的解決方案是 BoundedChannelFullMode:
var boundedChannel = Channel.CreateBounded<string>(
new BoundedChannelOptions(100) {
FullMode = BoundedChannelFullMode.Wait
});
注意到,這是一個列舉型別,事實上,它共有 Wait、DropNewest、DropOldest、DropWrite 四個取值,預設為 Wait。其中:
- Wait:當佇列已滿時,寫入資料時會回傳
false,直到佇列內有空間時可以繼續寫入。 - DropNewest:移除最新的資料,即從佇列尾部開始移除元素。
- DropOldest:移除最舊的資料,即從佇列頭部開始移除元素。
- DropWrite:可以寫入資料,但是資料會被立即丟棄。
除了佇列「滿」或者佇列「空」的問題,我們還考慮過多執行緒環境下的生產者-消費者模型可能會遇到的問題。值得慶幸的是,Channel 天生就支援多執行緒,我們可以透過 ChannelOptions 的 SingleWriter 和 SingleReader 來指定 Channel 是否是單一的消費者或者生產者,預設情況下,這兩個值都是 false:
var boundedChannel = Channel.CreateBounded<string>(
new BoundedChannelOptions(100) {
SingleWriter = true,
SingleReader = false,
FullMode = BoundedChannelFullMode.Wait
});
例如,透過以上程式碼片段,我們就可以建立出一個單生產者、多消費者的 Channel,對於 Channel 而言,其最重要的兩個成員分別是 Writer 和 Reader,前者對應生產者,型別定義為:ChannelWriter<T>;後者對應消費者,型別定義為:ChannelReader<T>,這一次,我們做到了真正意義上的讀寫分離:
// 生產者生產資料
channel.Writer.TryWrite("大漠孤煙直,長河落日圓。");
// 消費者消費資料
// 模式一:一次讀一個
while (await channel.Reader.WaitToReadAsync())
{
while (channel.Reader.TryRead(out var item))
{
// 在這裡寫具體的處理邏輯
}
}
// 模式二:一次全部讀出來
while (await channel.Reader.WaitToReadAsync())
{
await foreach (var item in channel.Reader.ReadAllAsync())
{
// 在這裡寫具體的處理邏輯
}
}
也許,你對這個話題意猶未盡,可我不得不非常遺憾的告訴你,這就是 Channel 最為核心的用法了。怎麼樣,是不是感覺非常簡單?這的確符合微軟一貫的作風,即:讓一個複雜的東西變得簡單好用。關於 Channel 更多的細節,這裡不再贅述,大家可以去閱讀官方文件。我發誓,MSDN 和 MDN 是我見過寫得最好的文件。
Channel 應用
OK,在對 Channel 有了一個基本的印象後,我們來看看它在具體場景中的應用。回到本文一開始作為引子出場的 FakeRPC,當我考慮為其新增 WebSocket 協定的支援時,我首當其衝要面對的問題是:如何把對一個方法的呼叫對映到 WebSocket 通訊上面。對於普通的 HTTP 協定而言,因為它遵循的是請求-回應模型,所以,它可以自然而然地和一個方法的呼叫產生聯繫。可當我們的視角切換到一個雙工通訊的 WebSocket 協定上時,這個問題就突然變得有趣起來。眾所周知,對於 WebSocket 來說,第一次連線是常規的 HTTP 協定,而一旦連線建立就不再需要 HTTP 協定。此時,雙方的交流將會是有來有回。最終,FakeRPC 採用了下面的方案來提供 WebSocket 協定的支援:
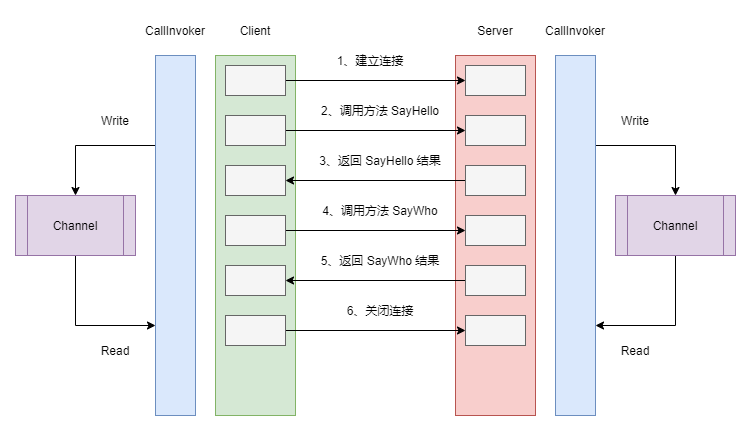 FakeRPC 如何支援 WebSocket 協定
FakeRPC 如何支援 WebSocket 協定
在這個方案中,CallInvoker 是真正負責處理請求的核心元件,對於用戶端來說,這個工作主要是按照請求的方法和參數組裝為 FakeRpcRequest,然後再呼叫 ClientWebSocket 實例的 SendAsync() 方法發送訊息給伺服器端。除此之外,它還需要從伺服器端接收訊息,因為每一條訊息都攜帶著 Id,因此,我們可以非常容易地分辨出哪一條訊息是回覆給自己的。在此基礎上,版主使用了一個背景執行緒從 Channel 中讀取訊息,這樣,發送訊息和接收訊息實際上是工作在兩個不同的執行緒上。對於伺服器端來說,在訊息的處理上是相似的,不同的是,伺服器端從 Channel 中讀取訊息是為了發送給用戶端,而用戶端從 Channel 讀取訊息則是為了傳遞結果給代理類。下面的程式碼,展示了上面提到的一部分用戶端的實作細節:
// 用戶端發送訊息
private async Task SendMessage(FakeRpcRequest request) {
var payload = await _messageSerializer.SerializeAsync<FakeRpcRequest>(request);
await _webSocket.SendAsync(new ArraySegment<byte>(payload), WebSocketMessageType.Binary, true, CancellationToken.None);
OnMessageSent?.Invoke(_webSocket, request);
}
// 用戶端從 Channel 中讀取訊息
private async Task ReadMessagesFromQueue() {
try {
while (await _messagesToReadQueue.Reader.WaitToReadAsync()) {
while (_messagesToReadQueue.Reader.TryRead(out var message)) {
try {
var response = await _messageSerializer.DeserializeAsync<FakeRpcResponse>(message.Array);
OnMessageReceived?.Invoke(_webSocket, response);
} catch (Exception e) {
_logger.LogError(e, $"Failed to send message due to {e.Message}");
}
}
}
}
catch (TaskCanceledException) { }
catch (OperationCanceledException) { }
catch (Exception e) {
_logger.LogError(e, $"Restart listen message queue due to {e.Message}");
ListenMessageQueue();
}
}
當然,ClientWebSocket 實例在收到訊息的時候,實際上是將訊息寫入 Channel,某種意義上你可以理解為,CallInvoker 同時承擔著生產者和消費者的角色,並且生產者和消費者執行在兩個不同的執行緒上:
var bytes = stream.ToArray();
var response = await _messageSerializer.DeserializeAsync<FakeRpcResponse>(bytes);
_logger?.LogInformation("Send response to {0}/{1}, payload:{3}", request.ServiceName, request.MethodName, response.Result);
_messagesToReadQueue.Writer.TryWrite(new ArraySegment<byte>(bytes));
此時,藉助於動態代理,我們可以非常輕鬆地呼叫一個 RPC 介面,並且它是以長連線的形式執行在 WebSocket 協定上:
var _clientFactory = serviceProvider.GetService<FakeRpcClientFactory>();
// 呼叫 GreetService
var greetProxy = _clientFactory.Create<IGreetService>(new Uri("ws://localhost:5000"), FakeRpcTransportProtocols.WebSocket, FakeRpcMediaTypes.Default);
var reply = await greetProxy.SayHello(new HelloRequest() { Name = "張三" });
reply = await greetProxy.SayWho();
// 呼叫 ICalculatorService
var calculatorProxy = _clientFactory.Create<ICalculatorService>(new Uri("ws://localhost:5000"), FakeRpcTransportProtocols.WebSocket, FakeRpcMediaTypes.Default);
var result = calculatorProxy.Random();
可以注意到,我們不僅在傳輸協定上實現了抽象,而且在訊息協定上實現了抽象,你可以像以前一樣自由地使用 MessagePack 或者 Protobuf,為了證明 Channel 真的對效能提升有用,這裡我放一張 FakeRPC 的 brenchmark 測試結果:
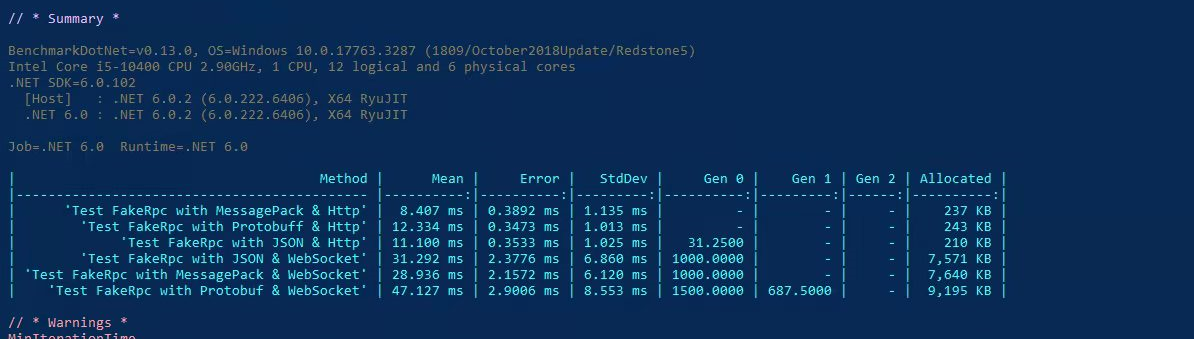 FakeRPC 不同通訊協定、訊息協定效能對比
FakeRPC 不同通訊協定、訊息協定效能對比
我們可以看到,MessagePack 不論是在 HTTP 協定下還是 WebSocket 協定下,始終都有著不俗的表現,這讓我開始期待,它能否在 TCP/IP 協定上繼續書寫這個傳奇,就在幾天前,我剛剛完成了 TCP/IP 協定下的二進位訊息定義,自從序列化和反序列化被抽象到 IMessageSerializer 介面以後,我們將會有更多的機會去支援更多的訊息協定,隨著 Ubisoft 官方官宣了新作,刺客教條:幻象,我對 FakeRPC 的這個名字的理解,已經延續到了刺客兄弟會的理念,即:Nothing is true,或者說,萬物皆虛。因為,從某種意義上來講,RPC 不過是隱藏了那些蜿蜒曲折的中間過程,讓你產生了可以像呼叫本機方法一樣呼叫遠端方法的錯覺,甚至在設計二進位訊息協定的時候,我突然意識到,我不過是再一次發明了 HTTP 協定。那麼,這一切還有意義嗎?當然有!做人嘛,開心就好了呀!
var buffer = new BufferBlock<int>();
// Producer
async static Task Producer(IEnumerable<int> values) {
foreach (var value in values) {
await buffer.SendAsync(value);
}
buffer.Complete();
}
// Consumer
async static Task Consumer(Action<int> process) {
while (await buffer.OutputAvailableAsync()) {
process?.Invoke(await buffer.ReceiveAsync());
}
}
var range = Enumerable.Range(0, 100);
await Task.WhenAll(Producer(range), Consumer(n => Console.WriteLine(n)));
BufferBlock 是微軟 TPL DataFlow 中的重要元件之一,其基本思想是:資料流是由一個又一個的資料塊組成,一個塊處理完畢後將會連結到下一個塊上。每一個塊以訊息的形式接收和快取來自一個或多個源的資料,當一個塊接收到資訊時,該塊會對輸入做出反應,與此同時,該塊的輸出將傳遞到下一個塊中。總而言之,除了 BufferBlock 以外,還有 ActionBlock、TransformBlock、BroadcastBlock 等等的塊,這裡我們會提到 BufferBlock,最大的原因是它採用了生產者-消費者模型,並且 BlockingCollection、BufferBlock、Channel 其實代表了 .NET 的不同階段,而回想起不同階段時的你,這註定是一個令人唏噓的故事啦!沿用這種思想,我們就找到了 Channel 的新玩法:
// GetFiles
Task<Channel<string>> GetFiles(string root) {
var filePathChannel = Channel.CreateUnbounded<string>();
var directoryInfo = new DirectoryInfo(root);
foreach (var file in directoryInfo.EnumerateFileSystemInfos()) {
filePathChannel.Writer.TryWrite(file.FullName);
}
filePathChannel.Writer.Complete();
return Task.FromResult(filePathChannel);
}
// Analyse
async Task<Channel<string>[]> Analyse(Channel<string> rootChannel) {
var counterChannel = Channel.CreateUnbounded<string>();
var errorsChannel = Channel.CreateUnbounded<string>();
while (await rootChannel.Reader.WaitToReadAsync()) {
await foreach (var filePath in rootChannel.Reader.ReadAllAsync()) {
var fileInfo = new FileInfo(filePath);
if (fileInfo.Extension == ".md") {
var totalWords = File.ReadAllText(filePath).Length;
counterChannel.Writer.TryWrite($"文章 [{fileInfo.Name}] 共 {totalWords} 個字元.");
} else {
errorsChannel.Writer.TryWrite($"路徑 [{filePath}] 是資料夾或者格式不正確.");
}
}
}
counterChannel.Writer.Complete();
errorsChannel.Writer.Complete();
return new Channel<string>[] { counterChannel, errorsChannel };
}
// Merge
async Task<Channel<string>> Merge(params Channel<string>[] channels) {
var mergeTasks = new List<Task>();
var outputChannel = Channel.CreateUnbounded<string>();
foreach (var channel in channels) {
var thisChannel = channel;
var mergeTask = Task.Run(async () => {
while (await thisChannel.Reader.WaitToReadAsync()) {
await foreach (var item in thisChannel.Reader.ReadAllAsync()) {
outputChannel.Writer.TryWrite(item);
}
}
});
mergeTasks.Add(mergeTask);
}
await Task.WhenAll(mergeTasks);
outputChannel.Writer.Complete();
return outputChannel;
}
// Run
var filePathChannel = await GetFiles(@"/hugo-blog/content/posts/");
var analysedChannels = await Analyse(filePathChannel);
var mergedChannel = await Merge(analysedChannels);
while (await mergedChannel.Reader.WaitToReadAsync()) {
await foreach (var item in mergedChannel.Reader.ReadAllAsync()) {
Console.WriteLine(item);
}
}
OK,這三個方法做了一件什麼樣的事情呢?我個人以為,這其實就是我們上面提到的資料流,首先,我們透過 GetFiles() 方法獲得指定目錄內的檔案資訊;然後,這些資訊交給 Analyse() 方法去做處理,這裡做的事情是統計出 markdown 格式檔案的字串,以及篩選出那些非 markdown 格式的檔案或者子目錄;最後,透過 Merge() 函式,我們將上一步的結果進行彙總輸出。如果用一幅圖來表示的話,它應該是下面這樣的流程:
 利用 Channel 實現資料流模式
利用 Channel 實現資料流模式
從某種意義上來講,這是一種「分治」策略,即:把一個大任務分解為若干個小任務,再將這些小任務的結果合併起來。很多年前,我曾在一本講並行程式的書上見過類似的程式碼片段,那個時候我已經對 Google 的 MapReduce 略有耳聞,後來又接觸到了 Parallel,我突然意識到,如果 Map() 和 Reduce() 兩個函式執行在一台遠端伺服器上,那麼這個過程可以認為是 RPC,而執行在遠端伺服器上的這些函式,其實是在並行地執行著某種運算,那麼這個過程可以認為是並行計算。當這些並行計算,使用的是世界各地的可伸縮計算資源時,那麼這個過程其實就是雲端運算。所以說,寫作這個過程還是挺有意思的,對不對?
本文小結
很多年前,Wesley 老大哥聊起怎麼把日誌寫到資料庫的話題,那個時候,我們都還沒有聽說過 Elasticsearch 這個詞彙。所以,我們當時能想到的方案,是打算用 BlockingCollection 來做一個阻塞式的佇列,換句話講,就是從 NLog 或者 Log4Net 中拿到日誌以後,將這些日誌全部放在 BlockingCollection 裡面,然後再考慮將其寫入到資料庫或者某種輸出源。後來,我陸陸續續地接觸了 NLog 裡的 Target,Serilog 裡的 Sink,大概知道了這一切是如何運作的,甚至這些日誌元件都可以支援把日誌輸出到不同的地方。從某種意義上看,這種認知上的變化,或許宣告著過去那種不成熟思維的過時,可恰恰是因為這些不成熟的思維,會不斷督促你重新整理對一件事物的認知,換句話講,我們的人生其實就是由無數個過去串聯起來的,無論曾經的你有多糗多頹多喪,它們都在不遺餘力地告訴你,我曾經真的在這個世界上存在過,就像今天有了更好用的 Channel,並不意味著我們過去的思考沒有意義,至少當我們提到生產者-消費者模型的時候,我會想起 Wesley 老大哥、想起 BlockingCollection。說不定啊,這就是時光對我這個記性太好的人的一種回應:你可以懷念過去,但請不要期待一切都能保持如初,在這個世界上,你只能做自己能做到的事情。