本文由网友
长空X投稿,欢迎转载、分享原文作者:长空 X(CSDN 同名“长空 X“,CkTools 的作者,github: https://github.com/hjkl950217)
原文链接:https://www.cnblogs.com/gtxck/articles/16293295.html
起因
今天在和懒得勤快聊天时谈到了树形表的处理时,发现目前我俩知道的查树形表都得递归查询,这种方式查询效率是非常底下且不好维护的,那么有没有一种又简单能平行查询的方式呢?后面我俩还真讨论了一种,他快速的修改到他的网站中了。
声明
文章中的几个方案是我们的讨论结果和一部分网络资料总结。设计方式千万种,文章中介绍的设计方式是针对大部分需要树形表的情况而不代表最优解!最优解已经是集合设计方式、人员水平、业务情况等因素综合之后的方案,这篇分享只是加速找到你的最优解。
什么是树形表?
关系型数据库表中,存放树形结构的表。例如某个字段需要选择分类,有一级、二级、...N 级,可以这样设计:
| ID | PID | 名字或内容 |
|---|---|---|
| 1 | 评论 1 | |
| 2 | 1 | 评论 2 |
| 3 | 1 | 评论 3 |
| 4 | 3 | 评论 4 |
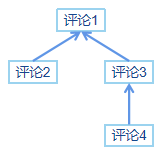
这样的数据可以组合成我们大学数据结构中的树,用来表达层级关系。这里的Id一般情况下用数字最好,但也有不是数字的情况,这点对选择方案可能有影响,后面会提到这一点。
这种数据结构的实体定义一般如下:
class CommentEntity
{
public int ID {get;set;}
public int PID {get;set;}
//.. 若干数据字段
public CommentEntity ParentNode {get;set;}
public List<CommentEntity> ChildNode {get;set;}
}
实体定义ParentNode指向父节点,ChildNode指向若干子节点。如果你有数据结构中的链表知识,能看出这 2 个字段起指针域的作用。
数据在数据库中按行存储,如果我们将数据获取出来后组装好ParentNode和ChildNode中的指向,然后就能按你的实际业务情况使用了。
有什么用?
有所属关系的都可以用这种方式存,例如: 权限关系、分类、类型、级别划分、行政区划、评论等等等...
但他麻烦之处在于查询不方便。比如想要查询一级分类下面的所有数据,按传统方式需要先查到id=1的一级分类,再查询PID=1的数据,再查询PID=刚才查询的数据ID 这样递归查询多次直到结束
目标
我们以评论为例
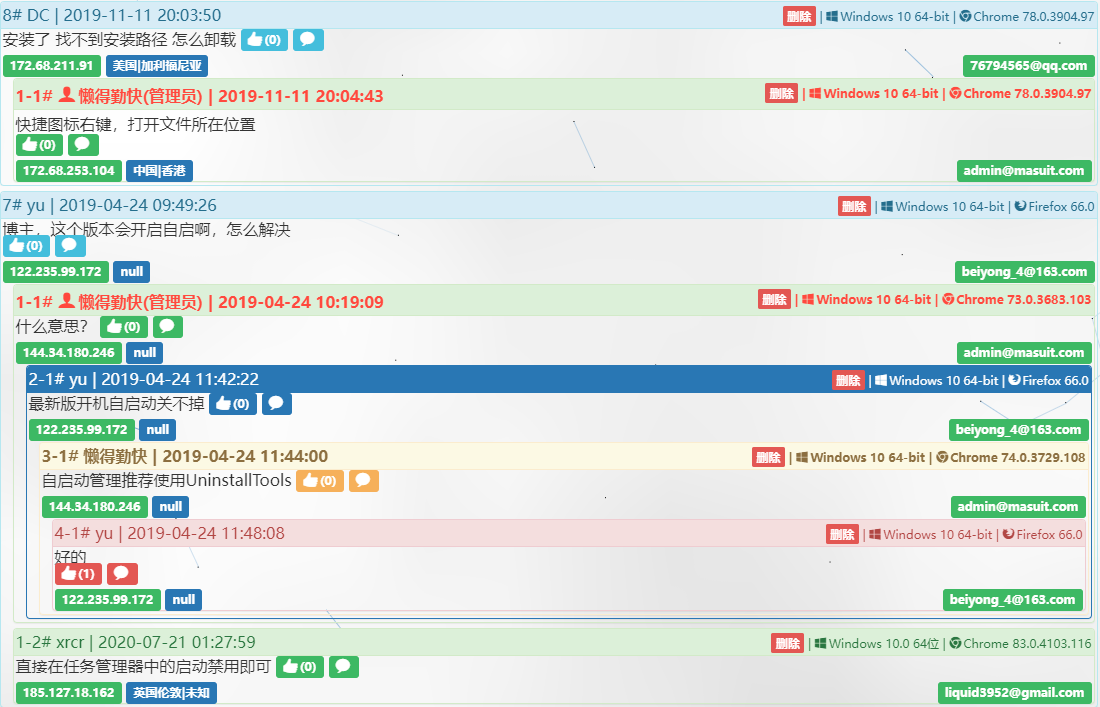
需要满足:
- 进页面时
分页查询出主评论,然后按层次关系显示回评 - 可以根据某一个评论查询下属所有评论
- 平行查询而不是递归查询
- 每个评论数据可以是主评判,也可以是子评论
方案 1: 使用 tag 标记树
这个方案是添加一个字段tag来标记整颗树,结构如下:
| ID | PID | Tag | 内容 |
|---|---|---|---|
| 1 | 文章 Id1 | 评论 1 | |
| 2 | 1 | 文章 Id1 | 评论 2 |
| 3 | 1 | 文章 Id1 | 评论 3 |
| 4 | 3 | 文章 Id1 | 评论 4 |
Tag用于数据库查询,ID和PID用于内存中组装数据,同时对Tag这一列建立非聚集索引。
查询方式:
这里新增的字段在每课树中都是一样的,最多查询 2 次数据库即可,然后自己在内存中用Pid重新排列引用关系,修剪掉不需要的数据。
第一次查询: 用评论 id 查询出文章 id(有文章 Id 时直接第二步)
第二次查询: 用文章 id 查询出所有数据
分页查询:查询后在内存中修剪掉不需要的数据
这种设计基于这些考虑:
- Id 是数字的情况下,连续的数据
大概率在磁盘上是连续存储,这能提高磁盘 IO 的效率。如果 Id 不是数字,用文章Id创建非聚集索引后也能快速查询。 - 在内存中组装引用关系是非常快的,而且不需要递归就能搞定.(遍历时用 PID 去查找,找到后直接向
ChildNode添加,同时向ParentNode赋值) - 设计逻辑简单,实习生水平以上的人就能轻松维护这种代码
缺点:如果一颗评论树有 1000 层,那无疑会获取巨量的无用数据
改进:使用 level 标记级别
增加级别字段:
| ID | PID | tag | level | 内容 |
|---|---|---|---|---|
| 1 | 文章 Id1 | 1 | 评论 1 | |
| 2 | 1 | 文章 Id1 | 2 | 评论 2 |
| 3 | 1 | 文章 Id1 | 2 | 评论 3 |
| 4 | 3 | 文章 Id1 | 3 | 评论 4 |
查询时附加上level,能减少一部分无用数据的传输,最后复用上面的组装代码。
方案 2: 使用 path 标记依赖路径
借用网上的一张图直接说明思路(未找到出处,侵权删除):
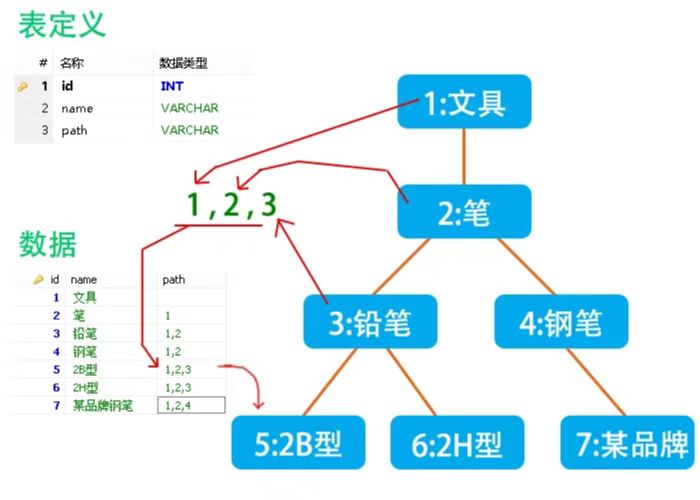
结合上面说的改造一下:
| ID | PID | Tag | Path | 内容 |
|---|---|---|---|---|
| 1 | 文章 Id1 | 评论 1 | ||
| 2 | 1 | 文章 Id1 | 1 | 评论 2 |
| 3 | 1 | 文章 Id1 | 1 | 评论 3 |
| 4 | 3 | 文章 Id1 | 1,2 | 评论 4 |
在写入子节点时需要知道父节点的 path,但一般来说这点是能满足的。Tag和Path用于数据库查询,ID和PID用于内存中组装数据。
查询方式:
查询全部: 仍文章 id 查询所有数据,然后在内存中用Pid组装
查询 id 为 2 及下面的数据:
第一次查询: 查询 id=2 的 path
第二次查询: 查询 id=2 or startwith $",2"
分页查询:
先用文章 id 按时间排序后查询前 X 个,然后进行第 2 次查询获取楼中楼的数据,第 2 次查询时可以拼多个 startwith。
同时也建议按需冗余level字段以减少查询,path 中虽然隐含了级别数据,但在查询时并不友好。
这种设计基于这些考虑:
- 同方案 1 差不多,并且理解成本更低
缺点:不算特别的缺点,在查询子节点数据用 path 过滤时,是利用不上索引的。
方案 3: 不设计楼中楼
借鉴知乎的设计,一看就懂系列:
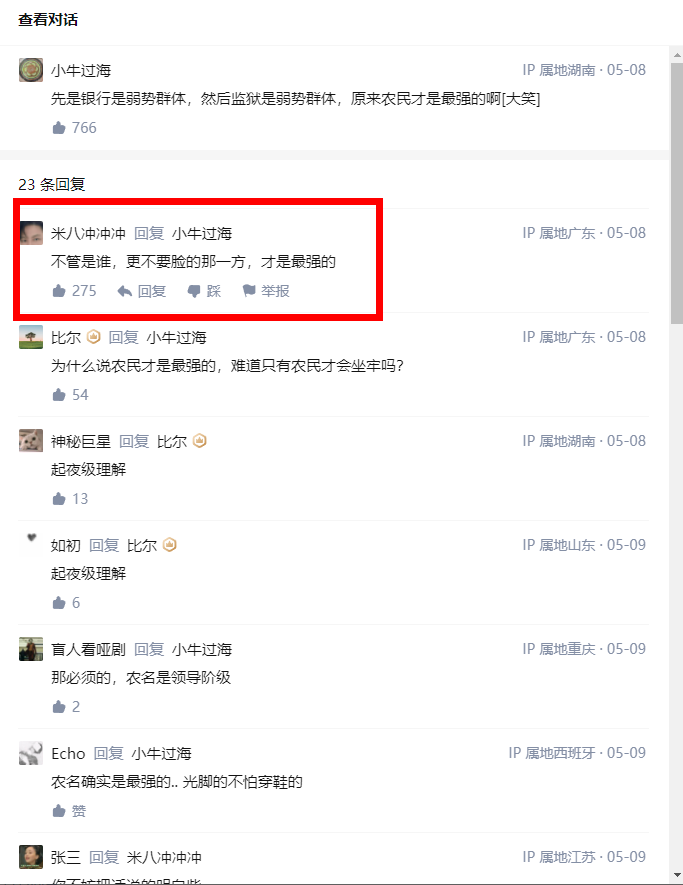
知乎的结构中只有评论和回评,回评也只需要保存上一次评论的 id 即可。这种方式不光设计简单,阅读体验也极好(楼中楼深了并非不好看)
| ID | PID | GroupID | Tag | 内容 |
|---|---|---|---|---|
| 1 | 1 | 文章 Id1 | 评论 1 | |
| 2 | 1 | 1 | 文章 Id1 | 评论 2 |
| 3 | 1 | 1 | 文章 Id1 | 评论 3 |
| 4 | 3 | 1 | 文章 Id1 | 评论 4 |
| 5 | 2 | 文章 Id1 | 评论 5 |
查询方式:
查询全部: 仍文章 id 查询所有PID is null的数据,然后在内存中用PID组装
查询 id 为 1 及下面的数据: 查询 GroupID = 1的数据。这种设计时不会单独查询回评的数据
优点:理解成本非常低,同时存储压力也小
方案 4:使用递归
前面不是说不使用递归吗?为什么这里还要提呢?因为:
- 有些团队中有人会固执的认为数据库不应该返回额外数据,也不应加冗余节点
- mysql 8.0 中增加了 RECURSIVE 来在数据库层面实现递归
- 其它无奈
所以如果前面 3 种方案都不适合你的情况,可能你还得回到递归这条路线上面,具体的这里就不提了,网上有许多这类文章。
总结
方案 123 都是通过冗余字段来降低查询成本和理解成本,并且利用不同存储的特性(数据库不适合运算、内存适合快速读写)来实现目标
方案 3 也是,同时也通过分析优化业务实现技术成本与客户体验的共赢。
方案 4 为兜底方案。
我个人比较推崇level+path的组合,这个组合不光能处理评论,也能很好的处理其它的树形结构,毕竟开发人员不能总是有机会影响业务需求不是?
如果你有更好的方案,欢迎留言讨论哦~
