浅谈UDP(数据包长度,收包能力,丢包及进程结构选择)
UDP 数据包长度,UDP 数据包的理论长度
udp 数据包的理论长度是多少,合适的 udp 数据包应该是多少呢?从 TCP-IP 详解卷一第 11 章的 udp 数据包的包头可以看出,udp 的最大包长度是 216-1 的个字节。由于 udp 包头占 8 个字节,而在 ip 层进行封装后的 ip 包头占去 20 字节,所以这个是 udp 数据包的最大理论长度是 216-1-8-20=65507。

然而这个只是 udp 数据包的最大理论长度。首先,我们知道,TCP/IP 通常被认为是一个四层协议系统,包括链路层、网络层、运输层、应用层。UDP 属于运输层,在传输过程中,udp 包的整体是作为下层协议的数据字段进行传输的,它的长度大小受到下层 ip 层和数据链路层协议的制约。
MTU 相关概念
以太网(Ethernet)数据帧的长度必须在 46-1500 字节之间,这是由以太网的物理特性决定的。这个 1500 字节被称为链路层的 MTU(最大传输单元)。因特网协议允许 IP 分片,这样就可以将数据包分成足够小的片段以通过那些最大传输单元小于该数据包原始大小的链路了。这一分片过程发生在网络层,它使用的是将分组发送到链路上的网络接口的最大传输单元的值。这个最大传输单元的值就是 MTU(Maximum Transmission Unit)。它是指一种通信协议的某一层上面所能通过的最大数据包大小(以字节为单位)。最大传输单元这个参数通常与通信接口有关(网络接口卡、串口等)。
在因特网协议中,一条因特网传输路径的“路径最大传输单元”被定义为从源地址到目的地址所经过“路径”上的所有 IP 跳的最大传输单元的最小值。
需要注意的是,loopback 的 MTU 不受上述限制,查看 loopback MTU 值:
[root@bogon ~]# cat /sys/class/net/lo/mtu
65536
IP 分包 udp 数据包长度的影响
如上所述,由于网络接口卡的制约,mtu 的长度被限制在 1500 字节,这个长度指的是链路层的数据区。对于大于这个数值的分组可能被分片,否则无法发送,而分组交换的网络是不可靠的,存在着丢包。IP 协议的发送方不做重传。接收方只有在收到全部的分片后才能 reassemble 并送至上层协议处理代码,否则在应用程序看来这些分组已经被丢弃。
假定同一时刻网络丢包的概率是均等的,那么较大的 IP datagram 必然有更大的概率被丢弃,因为只要丢失了一个 fragment,就导致整个 IP datagram 接收不到。不超过 MTU 的分组是不存在分片问题的。
MTU 的值并不包括链路层的首部和尾部的 18 个字节。所以,这个 1500 字节就是网络层 IP 数据报的长度限制。因为 IP 数据报的首部为 20 字节,所以 IP 数据报的数据区长度最大为 1480 字节。而这个 1480 字节就是用来放 TCP 传来的 TCP 报文段或 UDP 传来的 UDP 数据报的。又因为 UDP 数据报的首部 8 字节,所以 UDP 数据报的数据区最大长度为 1472 字节。这个 1472 字节就是我们可以使用的字节数。
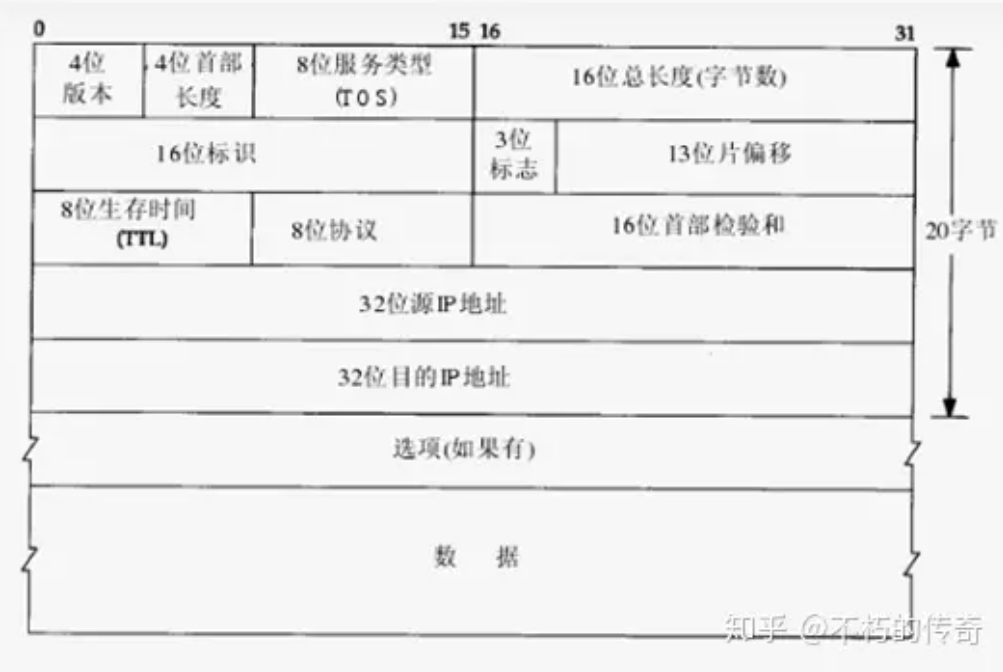
当我们发送的 UDP 数据大于 1472 的时候会怎样呢?这也就是说 IP 数据报大于 1500 字节,大于 MTU。这个时候发送方 IP 层就需要分片(fragmentation)。把数据报分成若干片,使每一片都小于 MTU。而接收方 IP 层则需要进行数据报的重组。而更严重的是,由于 UDP 的特性,当某一片数据传送中丢失时,接收方便无法重组数据报。将导致丢弃整个 UDP 数据报。因此,在普通的局域网环境下,将 UDP 的数据控制在 1472 字节以下为好。
进行 Internet 编程时则不同,因为 Internet 上的路由器可能会将 MTU 设为不同的值。如果我们假定 MTU 为 1500 来发送数据的,而途经的某个网络的 MTU 值小于 1500 字节,那么系统将会使用一系列的机制来调整 MTU 值,使数据报能够顺利到达目的地。鉴于 Internet 上的标准 MTU 值为 576 字节,所以在进行 Internet 的 UDP 编程时,最好将 UDP 的数据长度控件在 548 字节(576-8-20)以内。
UDP 丢包
udp 丢包是指网卡接收到数据包后,linux 内核的 tcp/ip 协议栈在 udp 数据包处理过程中的丢包,主要原因有两个:
1、udp 数据包格式错误或校验和检查失败。
2、应用程序来不及处理 udp 数据包。
对于原因 1,udp 数据包本身的错误很少见,应用程序也不可控,本文不讨论。
首先介绍通用的 udp 丢包检测方法,使用 netstat 命令,加-su 参数。
# netstat -su
Udp:
2495354 packets received
2100876 packets to unknown port received.
3596307 packet receive errors
14412863 packets sent
RcvbufErrors: 3596307
SndbufErrors: 0
从上面的输出中,可以看到有一行输出包含了"packet receive errors",如果每隔一段时间执行 netstat -su,发现行首的数字不断变大,表明发生了 udp 丢包。
下面介绍一下应用程序来不及处理而导致 udp 丢包的常见原因:
1、linux内核socket缓冲区设的太小 # cat /proc/sys/net/core/rmem_default
# cat /proc/sys/net/core/rmem_max
可以查看 socket 缓冲区的缺省值和最大值。
rmem_default 和 rmem_max 设置为多大合适呢?如果服务器的性能压力不大,对处理时延也没有很严格的要求,设置为 1M 左右即可。如果服务器的性能压力较大,或者对处理时延有很严格的要求,则必须谨慎设置 rmem_default 和 rmem_max,如果设得过小,会导致丢包,如果设得过大,会出现滚雪球。
2、服务器负载过高,占用了大量 cpu 资源,无法及时处理 linux 内核 socket 缓冲区中的 udp 数据包,导致丢包。
一般来说,服务器负载过高有两个原因:收到的 udp 包过多;服务器进程存在性能瓶颈。如果收到的 udp 包过多,就要考虑扩容了。服务器进程存在性能瓶颈属于性能优化的范畴,这里不作过多讨论。
3、磁盘 IO 忙
服务器有大量 IO 操作,会导致进程阻塞,cpu 都在等待磁盘 IO,不能及时处理内核 socket 缓冲区中的 udp 数据包。如果业务本身就是 IO 密集型的,要考虑在架构上进行优化,合理使用缓存降低磁盘 IO。
这里有一个容易忽视的问题:很多服务器都有在本地磁盘记录日志的功能,由于运维误操作导致日志记录的级别过高,或者某些错误突然大量出现,使得往磁盘写日志的 IO 请求量很大,磁盘 IO 忙,导致 udp 丢包。
对于运维误操作,可以加强运营环境的管理,防止出错。如果业务确实需要记录大量的日志,可以使用内存 log 或者远程 log。
4、物理内存不够用,出现 swap 交换
swap 交换本质上也是一种磁盘 IO 忙,因为比较特殊,容易被忽视,所以单列出来。
只要规划好物理内存的使用,并且合理设置系统参数,可以避免这个问题。
5)磁盘满导致无法 IO
没有规划好磁盘的使用,监控不到位,导致磁盘被写满后服务器进程无法 IO,处于阻塞状态。最根本的办法是规划好磁盘的使用,防止业务数据或日志文件把磁盘塞满,同时加强监控,例如开发一个通用的工具,当磁盘使用率达到 80%时就持续告警,留出充足的反应时间。
UDP 收包能力测试
测试环境
处理器:Intel(R) Xeon(R) CPU X3440 @ 2.53GHz,4 核,8 超线程,千兆以太网卡,8G 内存
模型 1
单机,单线程异步 UDP 服务,无业务逻辑,只有收包操作,除 UDP 包头外,一个字节数据。
测试结果
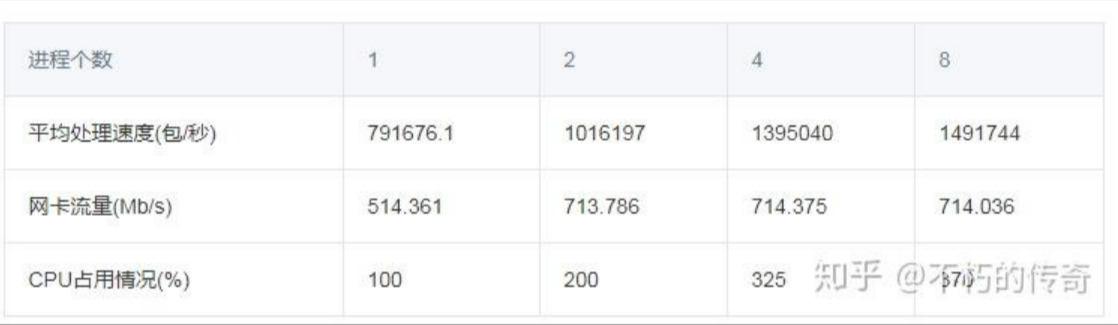
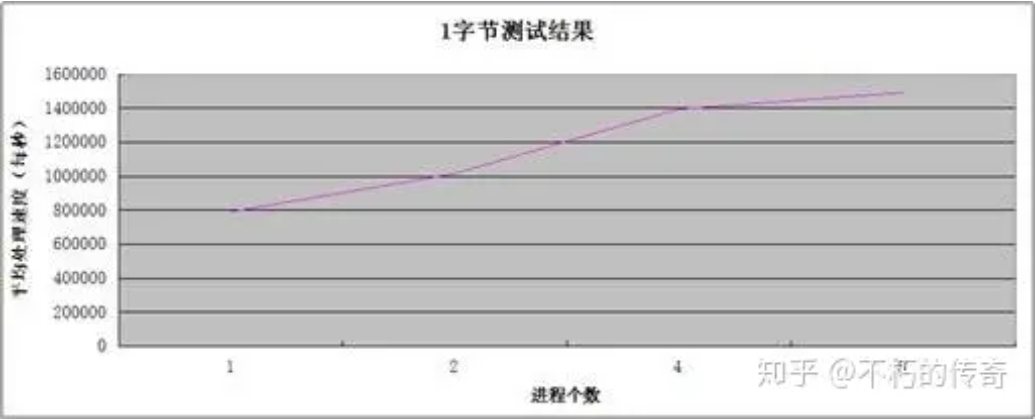
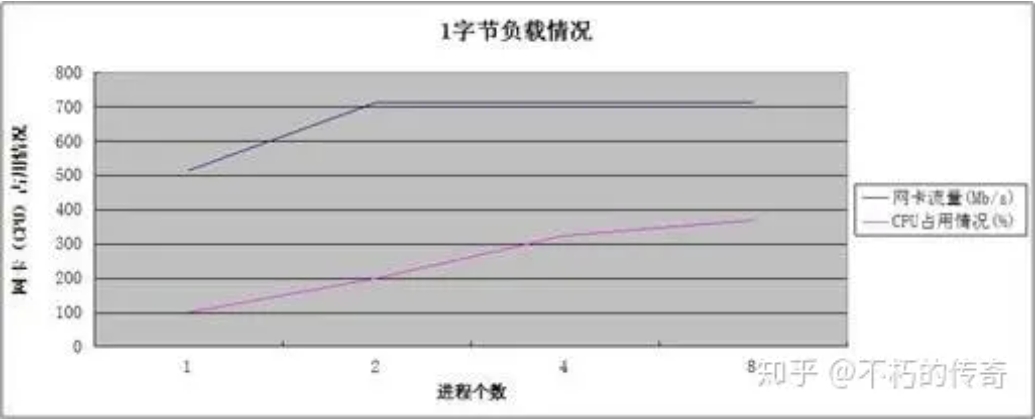
现象:
1、单机 UDP 收包处理能力可以每秒达到 150w 左右。
2、处理能力随着进程个数的增加而增强。
3、在处理达到峰值时,CPU 资源并未耗尽。
结论:
1、UDP 的处理能力还是非常可观的。
2、对于现象 2 和现象 3,可以看出,性能的瓶颈在网卡,而不在 CPU,CPU 的增加,处理能力的上升,来源于丢包(UDP_ERROR)个数的减少。
模型 2
其他测试条件同模型 1,除 UDP 包头外,一百个字节数据。
测试结果
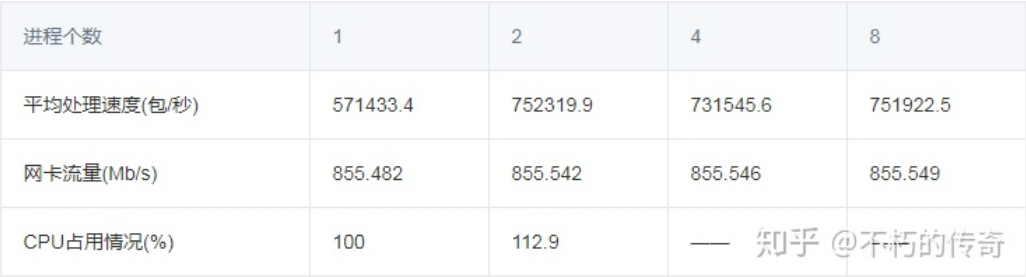
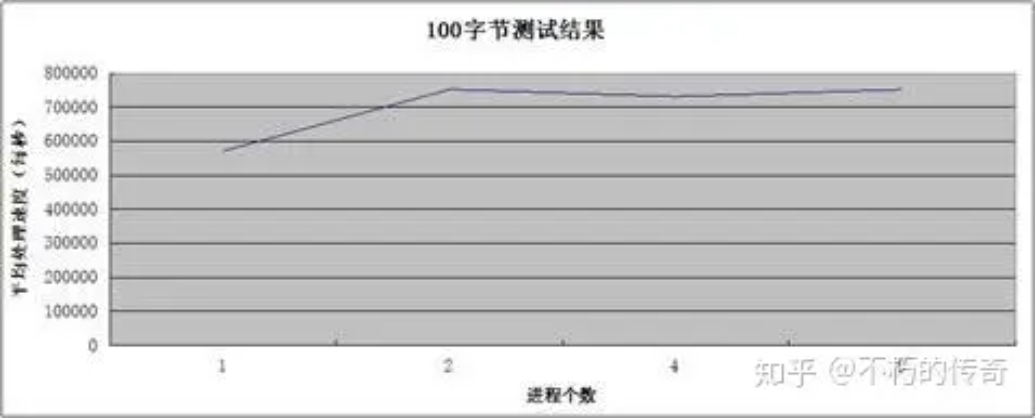
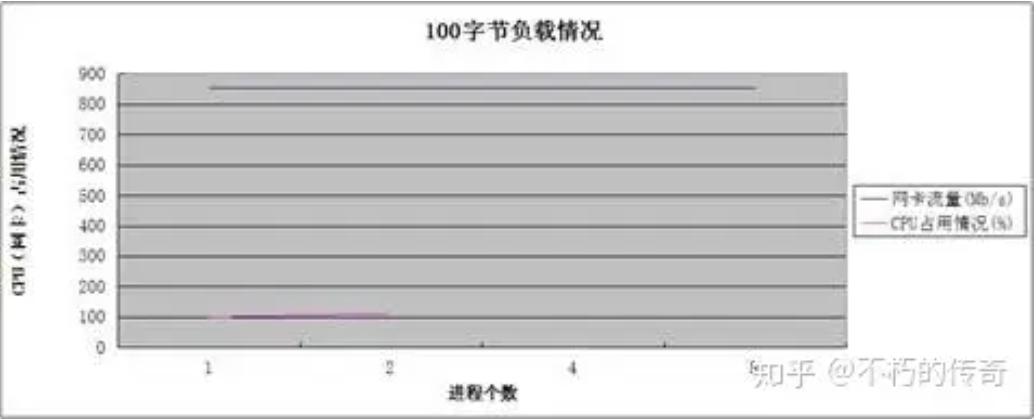
现象:
1、100 个字节的包大小,比较符合平常的业务情形。
2、UDP 的处理能力还是非常可观,单机峰值可以到达每秒 75w。
3、在 4,8 个进程时,没有记录 CPU 的占用情况(网卡流量耗尽),不过可以肯定的是,CPU 未耗尽。
4、随着进程个数的上升,处理能力没有明显提升,但是,丢包(UDP_ERROR)的个数大幅下降。
模型 3
单机,单进程,多线程异步 UDP 服务,多线程共用一个 fd,无业务逻辑,除 UDP 包头外,一个字节数据。
测试结果:
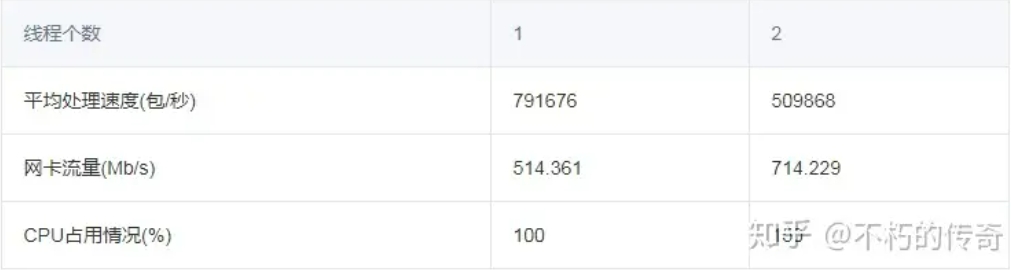
现象:
1、随着线程个数的增加,处理能力不升反降。
结论:
1、多线程共用一个 fd,会造成相当大的锁争用。
2、多线程共用一个 fd,当有包来时,会激活所有的线程,导致频繁的上下文切换。
最终结论:
1、UDP 处理能力非常可观,在日常的业务情形中,UDP 一般不会成为性能瓶颈。
2、随着进程个数的增加,处理能力未明显上升,但是丢包个数明显下降。
3、本次测试过程中,瓶颈在网卡,而不在 CPU。
4、采用多进程监听不同端口的模型,而不是多进程或多线程监听同一个端口。
总结
