
我宣布一下。
这个网站,终于被我用 AI 重构成了。
不是那种“让 AI 随手补几行代码”的参与度。
而是从页面重做、结构梳理、路由兼容、SEO、加载优化、内容接入、Markdown 清洗、最小测试集、CI,到这篇文章本身,AI 都深度参与了。
结果很直接。
效率真的高得离谱。
所以这篇文章,我想正式记录一下这次重构,也顺便聊聊一件事:
别抵触 AI。会不会被它替代先不谈,先学会怎么驾驭它,真的能事半功倍。
先看结果
首页
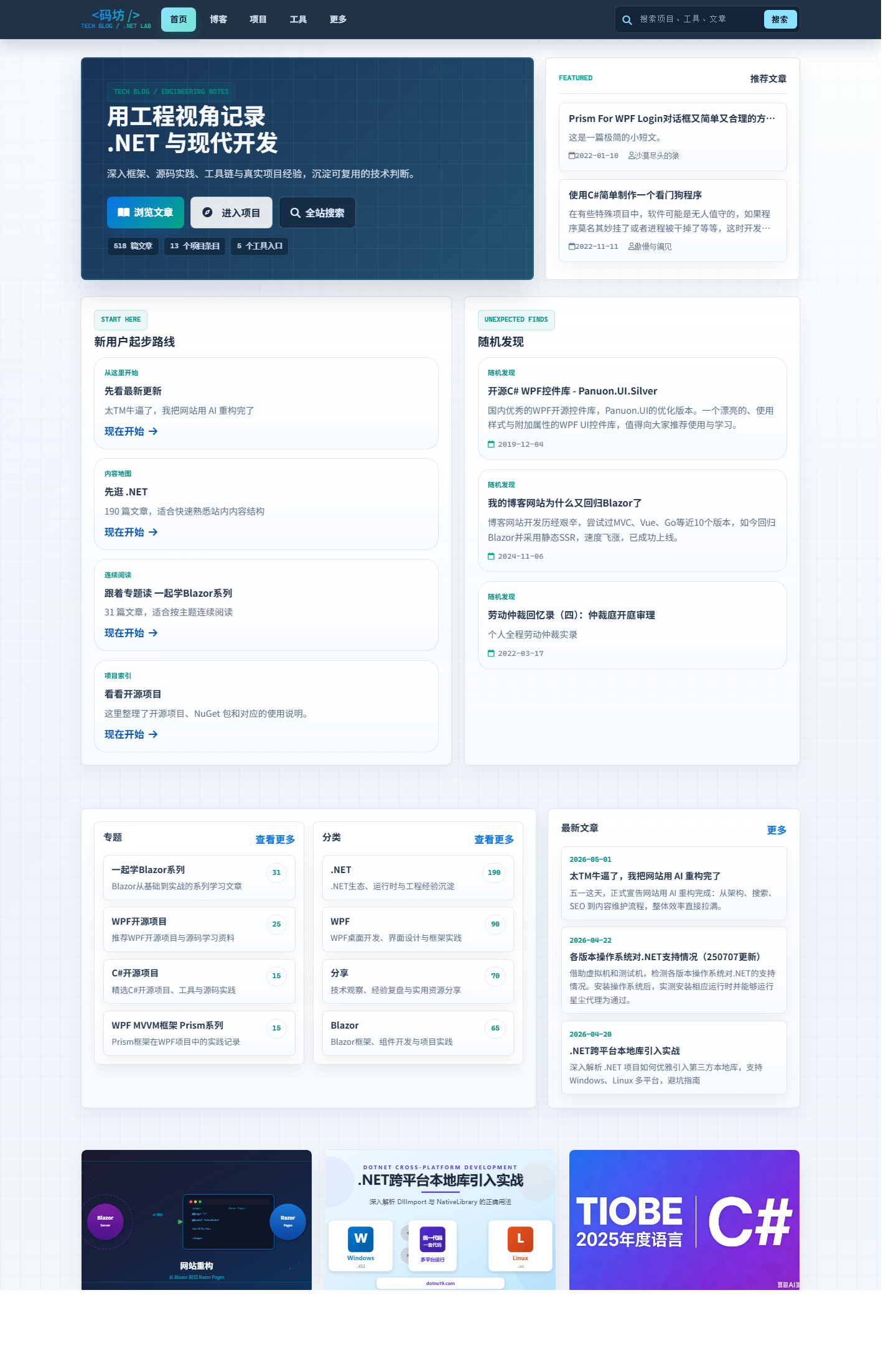
首页这次不再只是“把内容堆上去”。
我把信息层次重新梳理了:最新文章、项目、文档、工具入口更清晰,首屏更聚焦,也更像一个持续维护中的个人技术站,而不是零散页面的拼接。
它现在至少能做到两件事:
- 第一次进来的用户,知道这站点主要写什么、做什么。
- 老读者回来时,能更快找到新内容和常用入口。
搜索
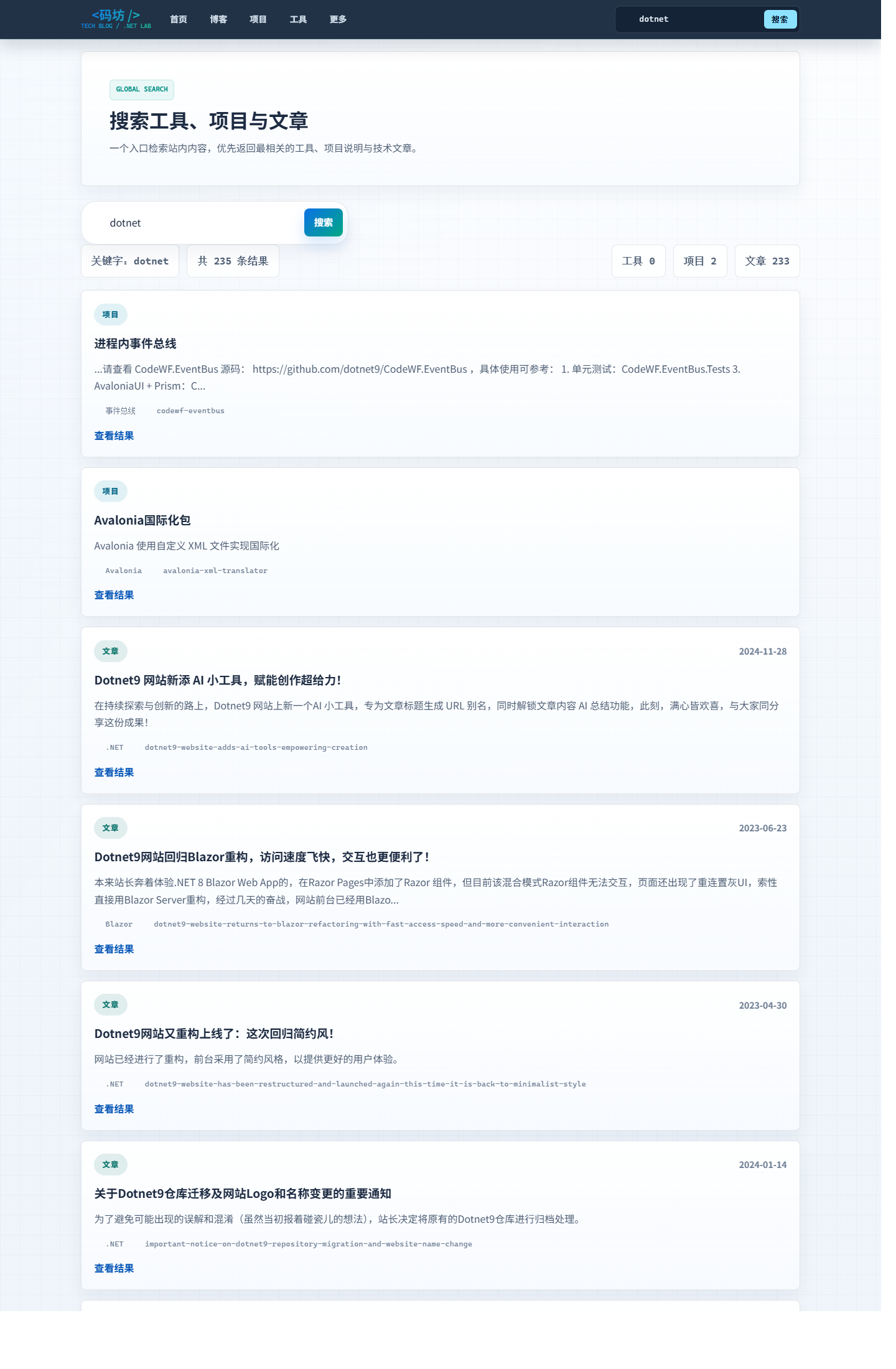
搜索是我这次很看重的一块。
以前很多个人站,搜索只是“能搜”,体验其实很一般。
这次我把搜索页、搜索路由、关键词处理、结果展示都顺手重做了,尤其补了一个很实际的细节:
搜索时增加了非法关键词过滤。
这个不是为了装样子,是真的有用。
实现上没有搞复杂,思路很直接:
- 先把用户输入做标准化处理。
- 再和
site/blocked-search-keywords.json里的词库做匹配。 - 命中后直接拦截,不让脏词继续进入搜索结果流程。
这样做有几个好处:
- 减少奇怪关键词污染搜索页和日志。
- 避免页面被低质量搜索流量反复命中。
- 对公开网站来说,能省掉不少没必要的脏活。
这个功能不大,但非常“站长视角”。
项目中心
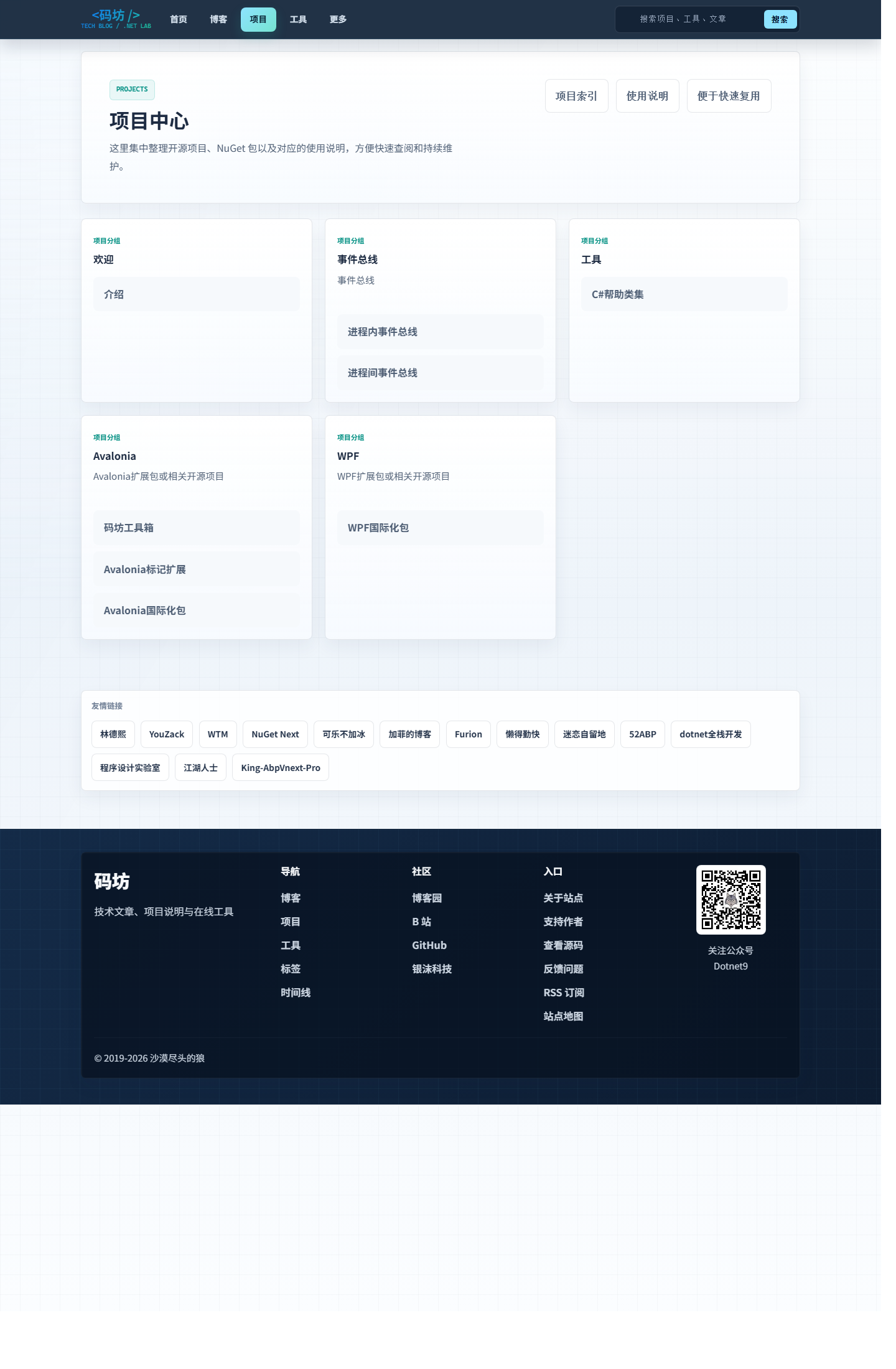
项目中心这块,我也重新整理过。
之前很多项目、组件、NuGet 包、工具入口散在不同文章里,读者不容易形成整体认知。
这次我把它们尽量收拢到了一个更清楚的入口里。
你可以更快看到:
- 我在做什么项目。
- 哪些是开源仓库。
- 哪些是工具型页面。
- 哪些内容适合直接拿去用。
这对我自己也很重要。
因为网站不只是“给别人看”,也是我自己的项目陈列柜和能力档案库。
文章详情页
文章页这次我盯得最细。
因为一个技术站最后好不好用,很多时候不看首页多花,而看正文页读起来舒不舒服。
这次我主要盯了几件事:
- Markdown 渲染别再出怪问题。
- 代码块显示要规整。
- 页面信息结构要更清楚。
- 资源引用方式尽量统一。
最近我还顺手清了一轮历史文章里的 Markdown 结构异常,比如老文章里混杂的旧格式代码围栏、反引号粘连、语言标签缺失之类的问题。
这类问题平时不显眼,但一旦累计多了,前端渲染就会非常难受。
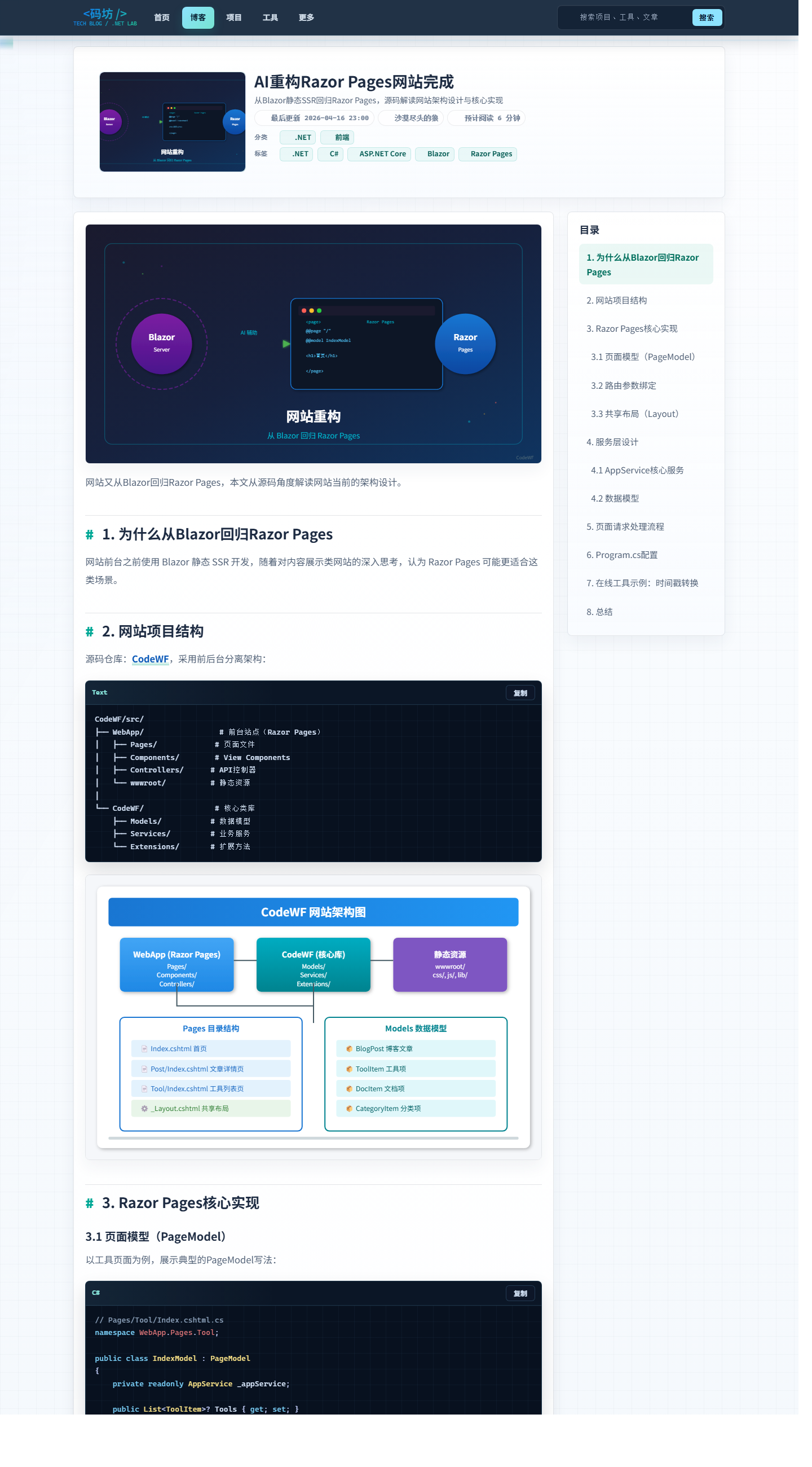
这次到底重构了什么
一句话说:
不是换了个皮,是把站点重新整理成了一个更像“产品”的状态。
我这次主要做了下面这些事:
- 页面结构重整。
- 路由兼容补齐。
- SEO 基础能力补强。
- 搜索体验重做。
- 非法关键词过滤。
- 资源域名独立。
- 加载性能优化。
- 内容热更新支持。
- README、最小测试集、CI 补齐。
- 历史 Markdown 结构问题清扫。
如果你是开发者,应该能明白这意味着什么。
很多时候,真正费时间的不是“写一个页面”,而是把一堆零散、历史包袱重、边角问题多的东西,慢慢收拾成一个能长期维护的仓库。
AI 在这件事上,确实帮了我很大忙。
讲点实现细节
1. 网站仓库和资源仓库分开
这次我继续保持了“双仓库”思路:
CodeWF/ # 网站仓库
Assets.Dotnet9/ # 资源仓库
CodeWF 负责站点本身的页面、组件、路由、渲染和 SEO。
Assets.Dotnet9 负责文章、配置、图片、导航、工具数据这些“内容资产”。
我自己越来越喜欢这种拆法。
因为内容站最怕的就是:改一篇文章,顺手把站点逻辑也搅进去;改一个页面,又把内容资源一起绑死。
拆开以后,脑子会清楚很多。
好处也很直接:
- 网站代码和内容资源职责清楚。
- 改文章时不必把站点逻辑一起搅进去。
- 更适合独立部署和缓存。
- 后面做内容同步、静态资源加速也更舒服。
2. 网站域名和资源域名分开
这个细节我特意说一下。
网站入口和资源访问,我是按两个域名部署的。
资源仓库里的图片、封面、文章内嵌资源,统一走这个域名:
所以你会看到本文里的图片引用,都是这种绝对地址:
https://img1.dotnet9.com/2026/05/codewf-homepage.png
这不是为了“显得专业”,而是为了后面少折腾。
网站页面和资源访问分开之后,很多事都更好处理。
比如:
- 静态资源缓存策略可以单独做。
- 资源迁移和 CDN 更灵活。
- 网站主域名压力更小。
- 文章内容更适合独立维护和发布。
3. 内容支持热更新
这个功能我自己很喜欢。
现在本地开发时,文章、JSON 配置、部分图片资源修改后,不必每次都重启站点。
背后用了 FileSystemWatcher 去监听资源目录变化。
监听的内容包括:
- Markdown
- JSON
- png/jpg/webp/svg 等图片资源
这类东西很朴素,甚至没什么“炫技感”。
但如果你平时真的自己写站、写文章,就会知道它有多省时间。
因为写文章最烦的,不是写,而是“改一段,重启一次,再看一遍”。
4. 加载速度这次也认真搞了,简单分享下怎么搞的细节
这块我没有去追那种特别花哨的指标词,思路反而很朴素:
先把最容易白白浪费性能的地方补上。
也就是该压的压,该缓存的缓存,该延后的延后,该优先的优先。
第一类,压缩。
这个我最先动手,因为它属于几乎没有副作用、但收益很稳的一类。
我在站点里直接开了 ResponseCompression,同时启用了 Brotli 和 Gzip,而且把 image/svg+xml 也一起加进了压缩范围。
像 HTML、CSS、JS、SVG 这种文本型资源,本来就很适合压缩,下发前先压一遍,首屏传输体积就会直接变小。
这种优化不性感,但很值。因为它不是“理论上会更快”,而是用户第一次打开页面时,第一段资源下载就真的会更轻。
第二类,静态资源缓存。
这一块我也补得比较实在,不是泛泛地说一句“做了缓存”就过去。
像 .css、.js、.png、.jpg、.webp、.svg、字体文件,还有部分 json/txt,现在都会带上:
Cache-Control: public,max-age=604800
也就是一周缓存。
道理很简单:用户不是每次打开页面,都该把老资源重新拉一遍。
尤其博客这种站点,很多资源本来就不是高频变化的。缓存命中起来之后,二次访问会舒服很多,页面也不会反复做没必要的请求。
另外我还配了 asp-append-version="true",比如站点里的 site.css、home.css、site.js、bootstrap.min.css 都带版本参数。
这样我就能比较放心地让资源缓存久一点,同时又不用怕样式或脚本更新后,用户还拿着旧文件。
好处很直接:
- 老资源可以放心缓存。
- 文件一旦更新,URL 自动变。
- 不用手动清缓存,也不用担心用户拿到旧样式。
第三类,图片加载。
图片这块我没有偷懒搞“一刀切”,而是分成了“列表图”和“首图”两种处理方式。
文章列表页、首页卡片、分类页这些非首屏核心图片,统一尽量走:
loading="lazy" decoding="async"
意思就是能晚一点加载就晚一点,能异步解码就别阻塞主线程。
但文章详情页顶部封面这种更关键的视觉元素,我就没有硬上懒加载,而是保留正常加载,同时补了 decoding="async" 和 fetchpriority="high",让真正该优先显示的图片优先显示。
我自己不太喜欢那种“所有图片都 lazy”就算优化完了的做法。实际页面里,不同图片的重要程度根本不一样,处理方式也不该一样。
第四类,页面渲染路径梳理。
这部分说白了,就是尽量减少一种很烦的情况:
页面内容还没出来,杂七杂八的资源先排队。
比如我对一些非关键外部资源做了延后处理:
- 对
cdnjs做了preconnect。 - Font Awesome 的样式表用了
media="print" onload="this.media='all'"这种方式异步加载。 - Prism 代码高亮样式也做了类似处理。
- 百度统计脚本不再一进页面就同步加载,而是等
window.load之后,再通过requestIdleCallback或setTimeout延后插入。
这些点单拆开看都不算大事,但合在一起,页面节奏就会顺很多。
先把真正该先看到的东西给用户,再去补图标、统计、增强样式,这个顺序我觉得比什么都重要。
第五类,SEO 和访问入口整理。
这一块表面上看像 SEO,其实我更愿意把它理解成“把网站入口重新理顺”。
因为内容站很多时候不是死在页面写不出来,而是死在:
- 搜索引擎不知道你这页到底是不是正文。
- 同一篇内容有多个入口,权重被打散。
- 分享出去只有个裸链接,卡片信息不完整。
- 你自己改了路由,历史入口和抓取入口一起断掉。
所以这次我把这部分补得比以前认真很多。
先说最基础的一层:canonical、Open Graph、Twitter Card。
现在页面会统一输出 canonical,文章详情页还会明确把 og:type 设成 article,og:image 直接走文章封面,同时把发布时间、更新时间、作者这些信息也一起带上。
这些东西平时肉眼不一定直接看到,但很重要。
因为搜索引擎、社交平台、聚合工具首先要先判断:这到底是一篇文章,还是一个普通页面;它的主链接是谁;它的封面该用哪张图。
这些基础信息不完整的时候,你自己觉得“页面能打开就行”,但搜索和分享系统可不这么想。
再往下一层,我把文章页的结构化数据也补了。
不是只写个标题 description 完事,而是直接输出了 Article 类型的 JSON-LD,把这些信息都带进去:
headlinedescriptionimagedatePublisheddateModifiedauthorpublishermainEntityOfPage
这玩意对普通读者几乎没存在感,但对搜索引擎理解页面类型、正文身份、发布时间这些信息很有帮助。
再说 RSS 和 sitemap,这两个我也不是摆个壳子出来。
RSS 现在会自动输出最近 10 篇文章,不是留个空链接装样子。
而 sitemap 也不只是首页一条,而是把这些入口都整理进去了:
- 首页
- 博客列表
- 分类页
- 专题页
- 标签页
- 文档页
- 工具页
- 每篇文章详情页
而且每个节点都会带 lastmod、changefreq、priority。
这看起来很基础,但对抓取路径特别关键。因为你等于是在明确告诉搜索引擎:哪些页更重要,哪些页更新更频繁,哪些内容值得优先抓。
还有一个我自己比较在意的小细节,是 robots 的控制。
像搜索结果这种页面,本来就不适合被当成核心内容页去收录,所以我会给特定入口加 noindex,follow,避免一些没必要的页面跑去参与索引。
这类处理很像打扫卫生,平时不显眼,但能少很多后续麻烦。
最后是访问入口和兼容路由。
这次我顺手把 /blog、/search、/doc、/sitemap.xml 这些更直觉的入口也保留下来了。
这不只是为了“看起来网址更好看”,而是为了两件事:
- 用户和爬虫更容易理解网站结构。
- 以后就算页面组织方式继续调整,历史入口和常见访问路径也不至于一下子全断。
所以严格说,这部分不完全等于“浏览器渲染更快”。
但对一个内容站来说,访问效率从来不只是前端那几百毫秒,还包括你怎么被发现、怎么被抓取、怎么被分享、怎么不把权重浪费掉。
所以这一整块,我都把它算进了这次优化里。
这些东西单独看都不夸张。
但一项一项堆起来,体感差别其实很明显。
很多时候,网站变快不是靠某一个“神优化”,而是把这些本来就该做的小事,一件一件做对。
如果你想直接把这个仓库跑起来
这部分我也写直接一点,免得有人看完觉得“好像挺能打”,结果真想跑起来的时候没入口。
1. 先拉两个仓库
git clone https://github.com/dotnet9/CodeWF.git
git clone https://github.com/dotnet9/Assets.Dotnet9.git
思路很简单,一个放站点代码,一个放内容资源。
2. 本地把资源目录指过去
$env:Site__LocalAssetsDir = "D:\github\owner\Assets.Dotnet9"
dotnet run --project D:\github\owner\CodeWF\src\WebApp
也就是说,站点启动的时候,会直接去读资源仓库里的文章和配置。
3. 文章放哪
文章按这种结构放:
YYYY/MM/slug.md
例如:
2026/05/labor-day-ai-rebuilt-my-site.md
4. 站点配置在哪里改
常见内容都在资源仓库的 site 目录里。
比如:
site/categories.jsonsite/albums.jsonsite/doc/navigation.jsonsite/tools/tools.jsonsite/blocked-search-keywords.json
也就是说,这个站点不是那种强依赖后台 CMS 才能维护的结构。
改 Markdown、改 JSON、改图片,基本就能完成大多数内容更新。
AI 这次到底帮我做了什么
这部分我想单独说。
因为很多人现在一提 AI,要么过度神化,要么本能抗拒。
我自己的感受是:
AI 最有价值的地方,不是替你思考,而是帮你把执行速度拉起来。
这次它主要帮我做了这些事:
- 梳理重构思路。
- 细化页面和路由调整。
- 补 README、CI、最小测试集。
- 清理历史 Markdown 结构问题。
- 协助整理文章结构。
- 生成和调整文章封面 SVG。
- 帮我把零碎工作串成完整闭环。
以前很多活,不是不会做。
是太碎、太杂、太耗神,拖着拖着就不想动了。
现在有了 AI,只要方向清楚、验收严格,它真的可以把很多“懒得做”的工作推着往前走。
以后我还会继续让 AI 帮我做更多工具
这个我也提前说一下。
后面我会继续基于这个网站,做更多在线工具。
但我不想一上来就追求大而全。
我的思路很简单:
先满足站长自己的真实需求。缺什么工具,就先让 AI 帮我开发一个。
比如:
- 内容处理小工具
- 开发辅助小工具
- 图片或文本转换工具
- 更贴近日常写站、写代码、写文章的实用工具
这样做有两个好处。
第一,工具不是为了凑数,而是真的会用。
第二,有真实使用场景,工具才更容易被慢慢打磨出来。
有人说,现在做这种网站意义不大了
这个话,我其实能理解。
如果只从流量、变现、平台分发效率去看,很多独立技术站确实不一定是最优解。
所以如果有人说:
“不过现在感觉做这种网站的意义不大了。”
我的回答其实很直接:
是的,我认同一半。
对我的意义,主要不是非得有多少人看。
更重要的是两件事:
- 展示自己这几年的文章记录。
- 满足一下成就感。
有人愿意看,当然开心。
没人看,我也照样会继续做,哈哈。
因为它本来就是我自己的内容阵地、项目陈列柜,也是一个能长期沉淀东西的地方。
欢迎来提建议,也欢迎 PR
如果你用了这个网站,或者看了仓库代码,有任何反馈,我都很欢迎。
你可以去这两个仓库:
欢迎反馈的内容包括:
- 页面体验问题
- 搜索体验问题
- Markdown 渲染问题
- 资源组织建议
- 新工具想法
- 文案或错字修正
- 直接提 PR
不管是网站仓库还是资源仓库,都欢迎一起来完善。
最后一句
这次重构做完,我最大的感受不是“AI 真神”。
而是:
会用 AI 的人,真的会比原来轻松很多,也快很多。
别急着抵触它。
先学会怎么提需求,怎么拆任务,怎么验结果,怎么把它当成一个高效率协作助手。
你会发现,很多原本嫌麻烦、不想开工、总想拖着的事,现在真的能做起来。
最后顺手补一句。
本文同样也是 AI 辅助完成的,我负责方向、事实校对和最终定稿。
如果你也在折腾个人网站、内容站、工具站,欢迎交流。