
UDP 資料包長度,UDP 資料包的理論長度
UDP 資料包的理論長度是多少,合適的 UDP 資料包應該是多大呢?從 TCP-IP 詳解卷一第 11 章的 UDP 資料包標頭可以看出,UDP 的最大封包長度是 216-1 個位元組。由於 UDP 標頭佔用 8 個位元組,而在 IP 層封裝後的 IP 標頭佔用 20 個位元組,因此 UDP 資料包的最大理論長度是 216-1-8-20=65507。

然而這只是 UDP 資料包的最大理論長度。首先,我們知道 TCP/IP 通常被視為一個四層協定系統,包括鏈路層、網路層、傳輸層、應用層。UDP 屬於傳輸層,在傳輸過程中,UDP 封包整體是作為下層協定的資料欄位進行傳輸的,它的長度大小受到下層 IP 層和資料鏈路層協定的制約。
MTU 相關概念
乙太網路(Ethernet)資料幀的長度必須在 46-1500 位元組之間,這是由乙太網路的物理特性決定的。這個 1500 位元組被稱為鏈路層的 MTU(最大傳輸單元)。網際網路協定允許 IP 分段,這樣就可以將資料包分成足夠小的片段以通過那些最大傳輸單元小於該資料包原始大小的鏈路。這一段過程發生在網路層,它使用的是將分組發送到鏈路上的網路介面的最大傳輸單元的值。這個最大傳輸單元的值就是 MTU(Maximum Transmission Unit)。它是指一種通訊協定的某一層上面所能通過的最大資料包大小(以位元組為單位)。最大傳輸單元這個參數通常與通訊介面有關(網路介面卡、串列埠等)。
在網際網路協定中,一條網際網路傳輸路徑的「路徑最大傳輸單元」被定義為從來源位址到目的位址所經過「路徑」上的所有 IP 跳的最大傳輸單元的最小值。
需要注意的是,loopback 的 MTU 不受上述限制,查看 loopback MTU 值:
[root@bogon ~]# cat /sys/class/net/lo/mtu
65536
IP 分段對 UDP 資料包長度的影響
如上所述,由於網路介面卡的制約,MTU 的長度被限制在 1500 位元組,這個長度指的是鏈路層的資料區。對於大於這個數值的分組可能會被分段,否則無法發送,而分組交換的網路是不可靠的,存在著掉包。IP 協定的發送方不做重傳。接收方只有在收到全部分段後才能重新組合並送至上層協定處理程式碼,否則在應用程式看來這些分組已經被丟棄。
假定同一時刻網路掉包的機率是均等的,那麼較大的 IP datagram 必然有更大的機率被丟棄,因為只要遺失了一個 fragment,就導致整個 IP datagram 無法收到。不超過 MTU 的分組是沒有分段問題的。
MTU 的值並不包括鏈路層的標頭和尾部的 18 個位元組。所以,這個 1500 位元組就是網路層 IP 資料報的長度限制。因為 IP 資料報的標頭為 20 位元組,所以 IP 資料報的資料區長度最大為 1480 位元組。而這個 1480 位元組就是用來放置 TCP 傳來的 TCP 報文段或 UDP 傳來的 UDP 資料報的。又因為 UDP 資料報的標頭為 8 位元組,所以 UDP 資料報的資料區最大長度為 1472 位元組。這個 1472 位元組就是我們可以使用的位元組數。
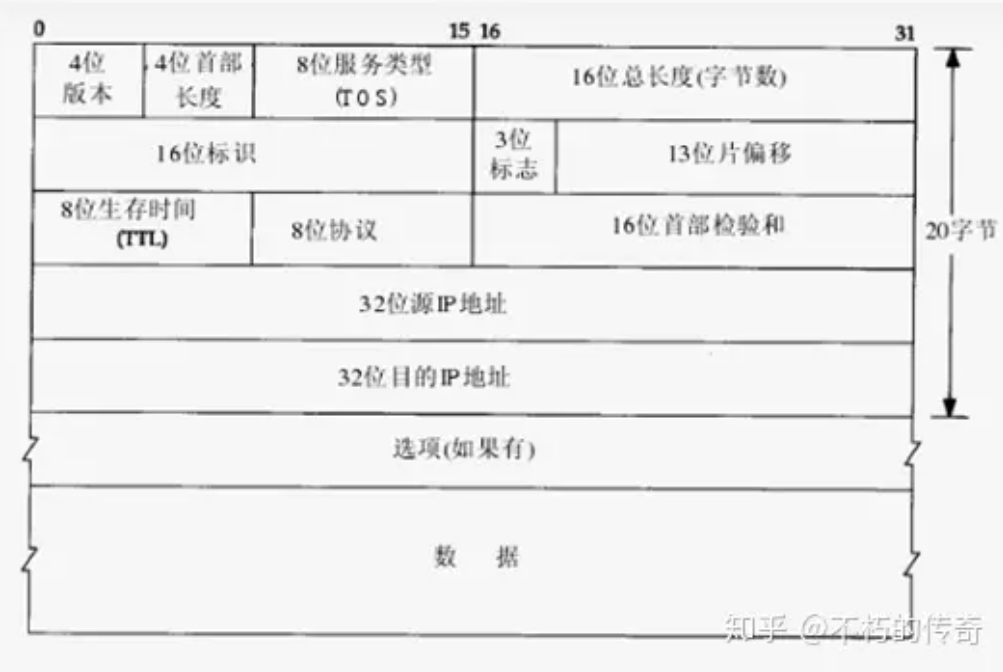
當我們發送的 UDP 資料大於 1472 時會怎麼樣呢?這也就是說 IP 資料報大於 1500 位元組,大於 MTU。這個時候發送方 IP 層就需要分段(fragmentation)。把資料報分成若干片,使每一片都小於 MTU。而接收方 IP 層則需要進行資料報的重組。而更嚴重的是,由於 UDP 的特性,當某一片資料在傳送中遺失時,接收方便無法重組資料報,將導致丟棄整個 UDP 資料報。因此,在一般的區域網路環境下,將 UDP 的資料控制在 1472 位元組以下為佳。
進行 Internet 程式設計時則不同,因為 Internet 上的路由器可能會將 MTU 設為不同的值。如果我們假定 MTU 為 1500 來發送資料,而途經的某個網路的 MTU 值小於 1500 位元組,那麼系統將會使用一系列的機制來調整 MTU 值,使資料報能夠順利到達目的地。鑑於 Internet 上的標準 MTU 值為 576 位元組,所以在進行 Internet 的 UDP 程式設計時,最好將 UDP 的資料長度控制在 548 位元組(576-8-20)以內。
UDP 掉包
UDP 掉包是指網卡接收到資料包後,Linux 核心的 TCP/IP 協定棧在 UDP 資料包處理過程中的掉包,主要原因有兩個:
- UDP 資料包格式錯誤或校驗和檢查失敗。
- 應用程式來不及處理 UDP 資料包。
對於原因 1,UDP 資料包本身的錯誤很少見,應用程式也不可控,本文不討論。
首先介紹通用的 UDP 掉包檢測方法,使用 netstat 命令,加上 -su 參數。
# netstat -su
Udp:
2495354 packets received
2100876 packets to unknown port received.
3596307 packet receive errors
14412863 packets sent
RcvbufErrors: 3596307
SndbufErrors: 0
從上面的輸出中,可以看到有一行輸出包含了 "packet receive errors",如果每隔一段時間執行 netstat -su,發現行首的數字不斷變大,表明發生了 UDP 掉包。
下面介紹一下應用程式來不及處理而導致 UDP 掉包的常見原因:
1. Linux 核心 socket 緩衝區設得太小
# cat /proc/sys/net/core/rmem_default
# cat /proc/sys/net/core/rmem_max
可以查看 socket 緩衝區的預設值和最大值。
rmem_default 和 rmem_max 設為多大合適呢?如果伺服器的效能壓力不大,對處理延遲也沒有很嚴格的要求,設為 1M 左右即可。如果伺服器的效能壓力較大,或者對處理延遲有很嚴格的要求,則必須謹慎設定 rmem_default 和 rmem_max,如果設得過小,會導致掉包;如果設得過大,會出現雪球效應。
- 伺服器負載過高,佔用了大量 CPU 資源,無法及時處理 Linux 核心 socket 緩衝區中的 UDP 資料包,導致掉包。
一般來說,伺服器負載過高有兩個原因:收到的 UDP 封包過多;伺服器程序存在效能瓶頸。如果收到的 UDP 封包過多,就要考慮擴容了。伺服器程序存在效能瓶頸屬於效能最佳化的範疇,這裡不作過多討論。
- 磁碟 I/O 忙碌
伺服器有大量 I/O 操作,會導致程序阻塞,CPU 都在等待磁碟 I/O,不能及時處理核心 socket 緩衝區中的 UDP 資料包。如果業務本身就是 I/O 密集型的,要考慮在架構上進行最佳化,合理使用快取降低磁碟 I/O。
這裡有一個容易忽略的問題:很多伺服器都有在本機磁碟記錄日誌的功能,由於維運誤操作導致日誌記錄的級別過高,或者某些錯誤突然大量出現,使得寫入磁碟的日誌 I/O 請求量很大,磁碟 I/O 忙碌,導致 UDP 掉包。
對於維運誤操作,可以加強營運環境的管理,防止出錯。如果業務確實需要記錄大量的日誌,可以使用記憶體日誌或遠端日誌。
- 實體記憶體不夠用,出現 swap 交換
swap 交換本質上也是一種磁碟 I/O 忙碌,因為比較特殊,容易被忽略,所以單獨列出。
只要規劃好實體記憶體的使用,並且合理設定系統參數,可以避免這個問題。
- 磁碟滿導致無法 I/O
沒有規劃好磁碟的使用,監控不到位,導致磁碟被寫滿後伺服器程序無法 I/O,處於阻塞狀態。最根本的辦法是規劃好磁碟的使用,防止業務資料或日誌檔案把磁碟塞滿,同時加強監控,例如開發一個通用的工具,當磁碟使用率達到 80% 時就持續告警,留出充足的反應時間。
UDP 收包能力測試
測試環境
處理器:Intel(R) Xeon(R) CPU X3440 @ 2.53GHz,4 核,8 超執行緒,千兆乙太網路卡,8G 記憶體
模型 1
單機,單執行緒非同步 UDP 服務,無業務邏輯,只有收包操作,除 UDP 標頭外,一個位元組資料。
測試結果
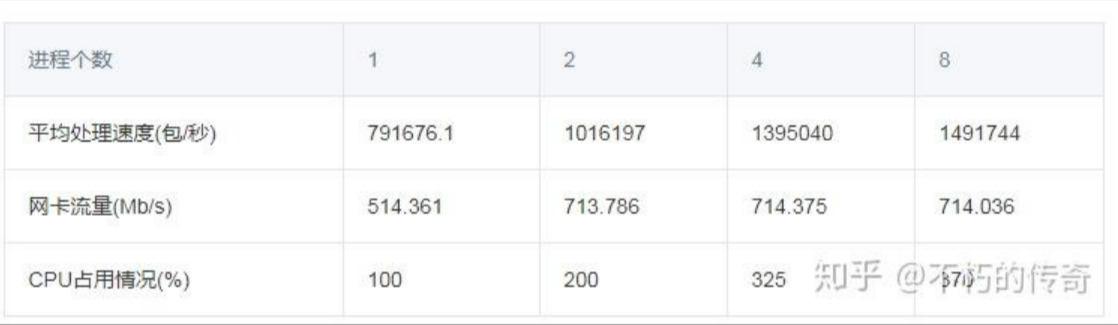
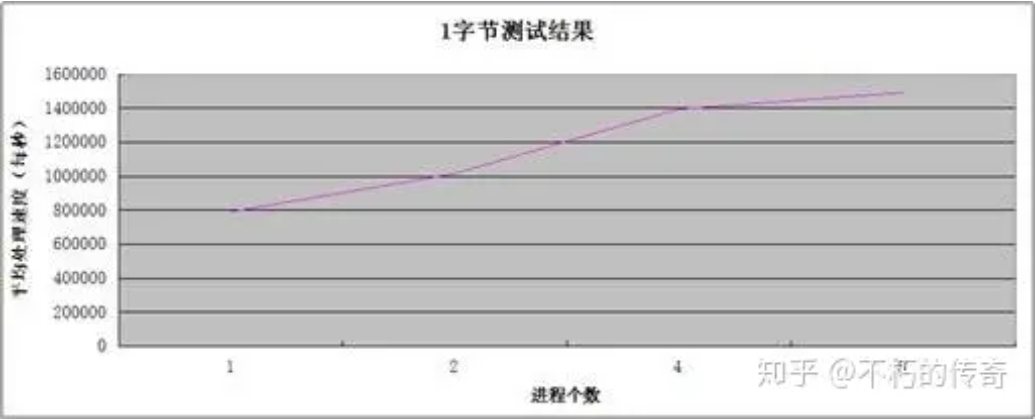
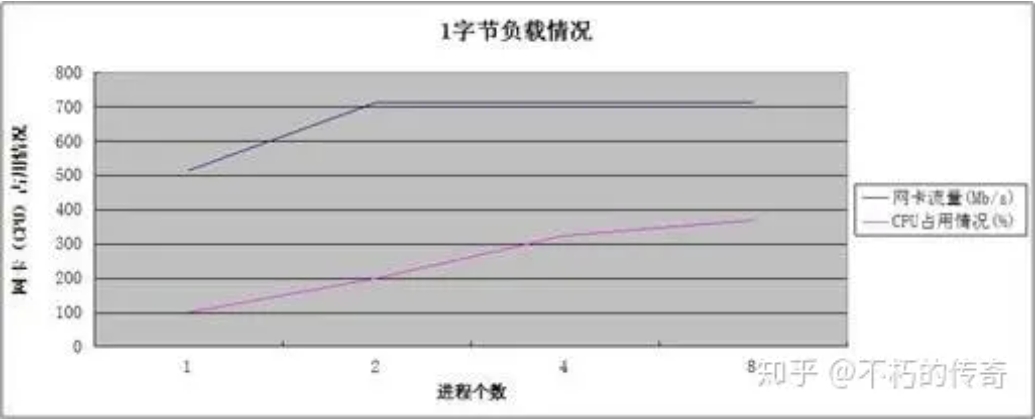
現象:
- 單機 UDP 收包處理能力可以達到每秒 150 萬左右。
- 處理能力隨著程序個數的增加而增強。
- 在處理達到峰值時,CPU 資源並未耗盡。
結論:
- UDP 的處理能力還是非常可觀的。
- 對於現象 2 和現象 3,可以看出,效能的瓶頸在網卡,而不在 CPU,CPU 的增加,處理能力的上升,來自於掉包(UDP_ERROR)個數的減少。
模型 2
其他測試條件同模型 1,除 UDP 標頭外,一百個位元組資料。
測試結果
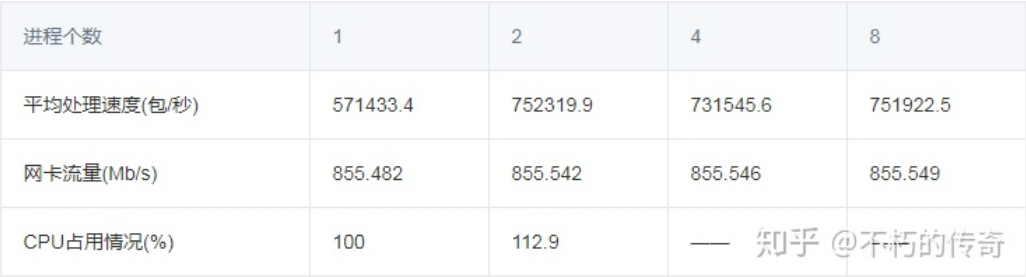
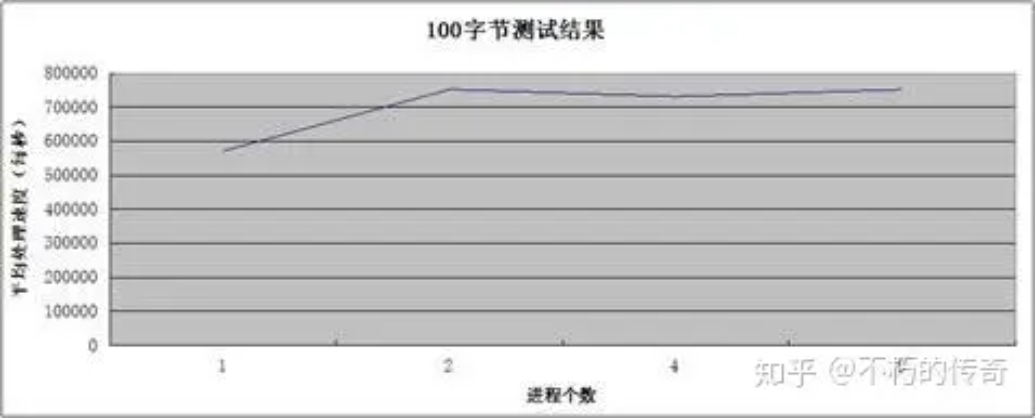
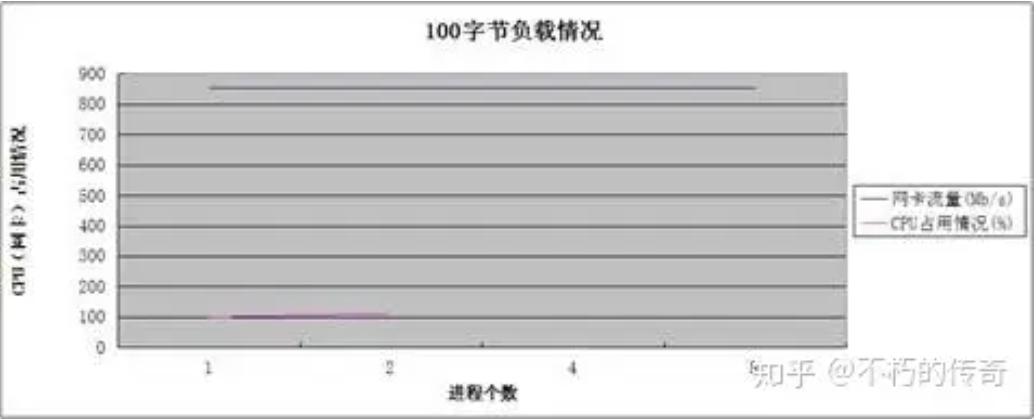
現象:
- 100 個位元組的封包大小,比較符合平常的業務情形。
- UDP 的處理能力還是非常可觀,單機峰值可以到達每秒 75 萬。
- 在 4、8 個程序時,沒有記錄 CPU 的佔用情況(網卡流量耗盡),不過可以肯定的是,CPU 未耗盡。
- 隨著程序個數的上升,處理能力沒有明顯提升,但是掉包(UDP_ERROR)的個數大幅下降。
模型 3
單機,單程序,多執行緒非同步 UDP 服務,多執行緒共用一個 fd,無業務邏輯,除 UDP 標頭外,一個位元組資料。
測試結果:
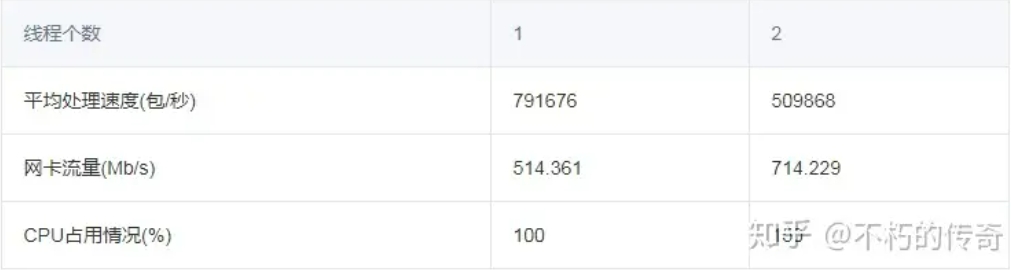
現象:
- 隨著執行緒個數的增加,處理能力不升反降。
結論:
- 多執行緒共用一個 fd,會造成相當大的鎖爭用。
- 多執行緒共用一個 fd,當有封包來時,會啟用所有的執行緒,導致頻繁的上下文切換。
最終結論:
- UDP 處理能力非常可觀,在日常的業務情形中,UDP 一般不會成為效能瓶頸。
- 隨著程序個數的增加,處理能力未明顯上升,但是掉包個數明顯下降。
- 本次測試過程中,瓶頸在網卡,而不在 CPU。
- 採用多程序監聽不同埠的模型,而不是多程序或多執行緒監聽同一個埠。
總結
