本文由網友
長空X投稿,歡迎轉載、分享原文作者:長空 X(CSDN 同名「長空 X」,CkTools 的作者,github: https://github.com/hjkl950217)
原文連結:https://www.cnblogs.com/gtxck/articles/16293295.html
起因
今天在和懶得勤快聊天時談到了樹形表的處理時,發現目前我倆知道的查樹形表都得遞迴查詢,這種方式查詢效率非常底下且不好維護,那麼有沒有一種又簡單能平行查詢的方式呢?後面我倆還真討論了一種,他快速的修改到他的網站中了。
聲明
文章中的幾個方案是我們的討論結果和一部分網路資料總結。設計方式千萬種,文章中介紹的設計方式是針對大部分需要樹形表的情況而不代表最優解!最優解已經是集合設計方式、人員水平、業務情況等因素綜合之後的方案,這篇分享只是加速找到你的最優解。
什麼是樹形表?
關聯式資料庫表中,存放樹狀結構的表。例如某個欄位需要選擇分類,有一級、二級、...N 級,可以這樣設計:
| ID | PID | 名字或內容 |
|---|---|---|
| 1 | 留言 1 | |
| 2 | 1 | 留言 2 |
| 3 | 1 | 留言 3 |
| 4 | 3 | 留言 4 |
這樣的資料可以組合成我們大學資料結構中的樹,用來表達階層關係。這裡的Id一般情況下用數字最好,但也有不是數字的情況,這點對選擇方案可能有影響,後面會提到這一點。
這種資料結構的實體定義一般如下:
class CommentEntity
{
public int ID {get;set;}
public int PID {get;set;}
//.. 若干資料欄位
public CommentEntity ParentNode {get;set;}
public List<CommentEntity> ChildNode {get;set;}
}
實體定義ParentNode指向父節點,ChildNode指向若干子節點。如果你有資料結構中的鏈結串列知識,能看出這 2 個欄位起指標域的作用。
資料在資料庫中按行儲存,如果我們將資料獲取出來後組裝好ParentNode和ChildNode中的指向,然後就能按你的實際業務情況使用了。
有什麼用?
有所屬關係的都可以用這種方式存,例如:權限關係、分類、類型、級別劃分、行政區劃、留言等等等...
但他麻煩之處在於查詢不方便。比如想要查詢一級分類下面的所有資料,按傳統方式需要先查到id=1的一級分類,再查詢PID=1的資料,再查詢PID=剛才查詢的資料ID 這樣遞迴查詢多次直到結束。
目標
我們以留言為例
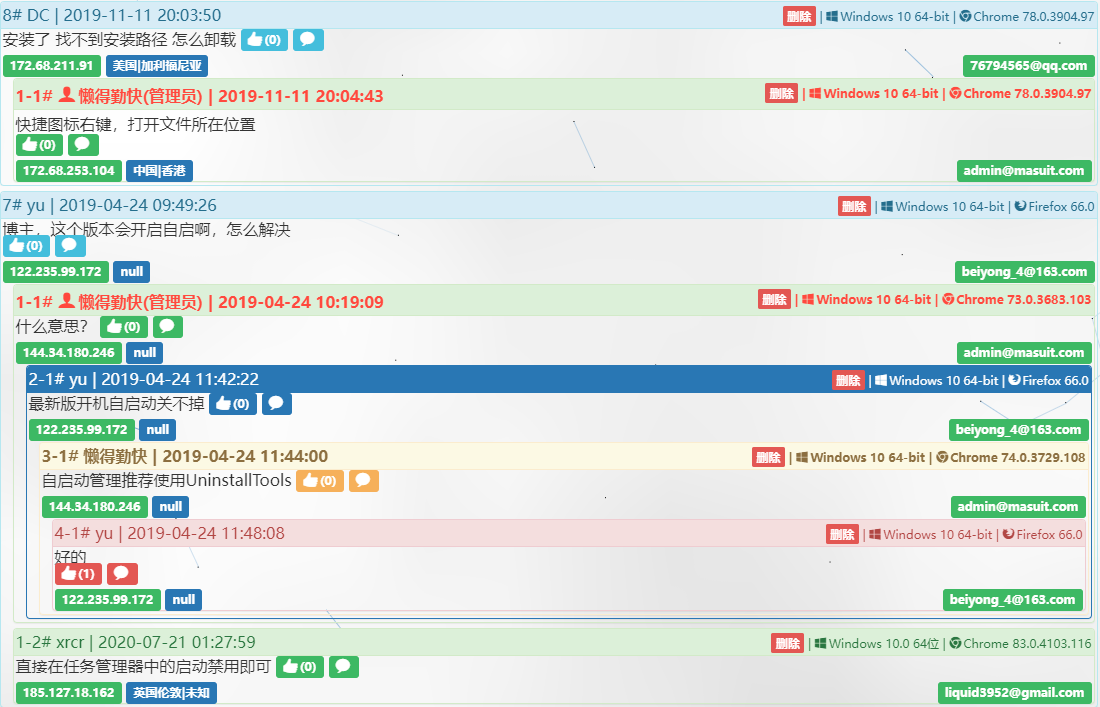
需要滿足:
- 進頁面時
分頁查詢出主留言,然後按層次關係顯示回覆 - 可以根據某一個留言查詢下屬所有留言
- 平行查詢而不是遞迴查詢
- 每個留言資料可以是主留言,也可以是子留言
方案 1: 使用 tag 標記樹
這個方案是添加一個欄位tag來標記整棵樹,結構如下:
| ID | PID | Tag | 內容 |
|---|---|---|---|
| 1 | 文章 Id1 | 留言 1 | |
| 2 | 1 | 文章 Id1 | 留言 2 |
| 3 | 1 | 文章 Id1 | 留言 3 |
| 4 | 3 | 文章 Id1 | 留言 4 |
Tag用於資料庫查詢,ID和PID用於記憶體中組裝資料,同時對Tag這一列建立非聚集索引。
查詢方式:
這裡新增的欄位在每棵樹中都是一樣的,最多查詢 2 次資料庫即可,然後自己在記憶體中用Pid重新排列引用關係,修剪掉不需要的資料。
第一次查詢: 用留言 id 查詢出文章 id(有文章 Id 時直接第二步)
第二次查詢: 用文章 id 查詢出所有資料
分頁查詢:查詢後在記憶體中修剪掉不需要的資料
這種設計基於這些考慮:
- Id 是數字的情況下,連續的資料
大概率在磁碟上是連續儲存,這能提高磁碟 IO 的效率。如果 Id 不是數字,用文章Id建立非聚集索引後也能快速查詢。 - 在記憶體中組裝引用關係是非常快的,而且不需要遞迴就能搞定。(遍歷時用 PID 去查找,找到後直接向
ChildNode添加,同時向ParentNode賦值) - 設計邏輯簡單,實習生水平以上的人就能輕鬆維護這種程式碼
缺點:如果一棵留言樹有 1000 層,那無疑會獲取巨量的無用資料
改進:使用 level 標記級別
增加級別欄位:
| ID | PID | tag | level | 內容 |
|---|---|---|---|---|
| 1 | 文章 Id1 | 1 | 留言 1 | |
| 2 | 1 | 文章 Id1 | 2 | 留言 2 |
| 3 | 1 | 文章 Id1 | 2 | 留言 3 |
| 4 | 3 | 文章 Id1 | 3 | 留言 4 |
查詢時附加上level,能減少一部分無用資料的傳輸,最後複用上面的組裝程式碼。
方案 2: 使用 path 標記依賴路徑
借用網上的一張圖直接說明思路(未找到出處,侵權刪除):
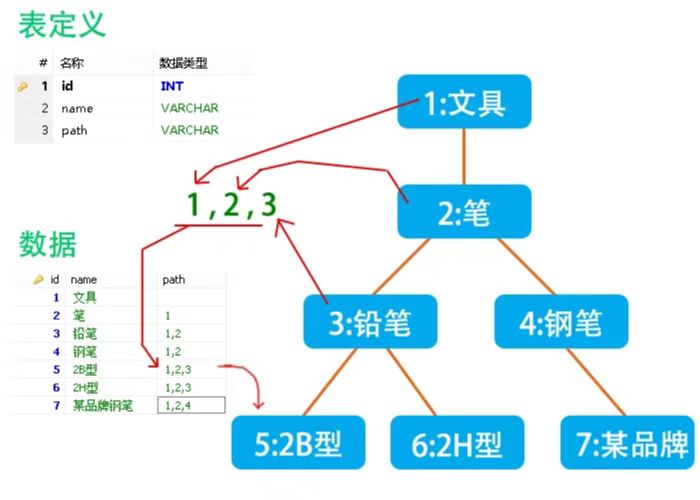
結合上面說的改造一下:
| ID | PID | Tag | Path | 內容 |
|---|---|---|---|---|
| 1 | 文章 Id1 | 留言 1 | ||
| 2 | 1 | 文章 Id1 | 1 | 留言 2 |
| 3 | 1 | 文章 Id1 | 1 | 留言 3 |
| 4 | 3 | 文章 Id1 | 1,2 | 留言 4 |
在寫入子節點時需要知道父節點的 path,但一般來說這點是能滿足的。Tag和Path用於資料庫查詢,ID和PID用於記憶體中組裝資料。
查詢方式:
查詢全部: 仍文章 id 查詢所有資料,然後在記憶體中用Pid組裝
查詢 id 為 2 及下面的資料:
第一次查詢: 查詢 id=2 的 path
第二次查詢: 查詢 id=2 or startwith $",2"
分頁查詢:
先用文章 id 按時間排序後查詢前 X 個,然後進行第 2 次查詢獲取樓中樓的資料,第 2 次查詢時可以拼多個 startwith。
同時也建議按需冗餘level欄位以減少查詢,path 中雖然隱含了級別資料,但在查詢時並不友好。
這種設計基於這些考慮:
- 同方案 1 差不多,並且理解成本更低
缺點:不算特別的缺點,在查詢子節點資料用 path 過濾時,是利用不上索引的。
方案 3: 不設計樓中樓
借鑑知乎的設計,一看就懂系列:
知乎的結構中只有留言和回覆,回覆也只需要保存上一次留言的 id 即可。這種方式不光設計簡單,閱讀體驗也極好(樓中樓深了並非不好看)
| ID | PID | GroupID | Tag | 內容 |
|---|---|---|---|---|
| 1 | 1 | 文章 Id1 | 留言 1 | |
| 2 | 1 | 1 | 文章 Id1 | 留言 2 |
| 3 | 1 | 1 | 文章 Id1 | 留言 3 |
| 4 | 3 | 1 | 文章 Id1 | 留言 4 |
| 5 | 2 | 文章 Id1 | 留言 5 |
查詢方式:
查詢全部: 仍文章 id 查詢所有PID is null的資料,然後在記憶體中用PID組裝
查詢 id 為 1 及下面的資料: 查詢 GroupID = 1的資料。這種設計時不會單獨查詢回覆的資料
優點:理解成本非常低,同時儲存壓力也小
方案 4:使用遞迴
前面不是說不使用遞迴嗎?為什麼這裡還要提呢?因為:
- 有些團隊中有人會固執的認為資料庫不應該返回額外資料,也不應加冗餘節點
- mysql 8.0 中增加了 RECURSIVE 來在資料庫層面實現遞迴
- 其他無奈
所以如果前面 3 種方案都不適合你的情況,可能你還得回到遞迴這條路線上面,具體的這裡就不提了,網上有許多這類文章。
總結
方案 123 都是透過冗餘欄位來降低查詢成本和理解成本,並且利用不同儲存的特性(資料庫不適合運算、記憶體適合快速讀寫)來實現目標
方案 3 也是,同時也透過分析優化業務實現技術成本與客戶體驗的共贏。
方案 4 為兜底方案。
我個人比較推崇level+path的組合,這個組合不光能處理留言,也能很好的處理其他的樹狀結構,畢竟開發人員不能總是有機會影響業務需求不是?
如果你有更好的方案,歡迎留言討論哦~